
Información de la Tarea
Estudiante: Andrés Cruz Chipol
Curso: Aprendizaje Profundo
Fecha de entrega: 28 de Mayo, 2026
Descripción de la Tarea
Con estos datos realizar un clasificador con redes neuronales. Se tienen 11 características y se deben clasificar los vinos por su calidad. Comparar la gráfica de pérdida contra época con tres optimizadores: Adam, SGD y SGD con momento y el atributo ‘nesterov’ habilitado.
Clasificación de calidad de vinos
Introducción
Construí una red neuronal basándonos en 11 características del conjunto de datos winequality-white.csv. Comparamos el desempeño y la convergencia de la red utilizando tres optimizadores diferentes: Adam, SGD tradicional, y SGD con momento Nesterov.
Se enfatiza que al inicio se usaron redes con pocas neuronas para encontrar un buen % de accuracy, sin embargo, ninguno pasaba del 55% aproximadamente. Fue hasta que incrementamos el número de capas ocultas que pudimos obtener un mayor porcentaje de aciertos.
Recalco que el tamano de la prueba es del 15% del conjunto de datos, ya que observe que los datos estaban muy desbalanceados, por lo que quise experimentar con el tamaño de prueba para obtener un mayor porcentaje de aciertos y al parecer funcionó. aun que seguramente no es lo mas adecuado para una red robusta.
Preparación de Datos
Use StandardScaler de Scikit-Learn para normalizar las características de entrada.
from sklearn.preprocessing import StandardScalerfrom sklearn.model_selection import train_test_splitimport numpy as npimport torchfrom torch import nn
torch.manual_seed(1)
scaler = StandardScaler()
data = np.loadtxt("winequality-white.csv", delimiter=';', skiprows=1)X = data[:,0:11]y = data[:,11]
X_train, X_test, y_train, y_test = train_test_split(X,y, random_state=99, stratify=y, test_size=0.15)
X_train = scaler.fit_transform(X_train)X_test = scaler.transform(X_test)
X_train = torch.tensor(X_train, dtype=torch.float32)X_test = torch.tensor(X_test, dtype=torch.float32)y_train = torch.tensor(y_train, dtype=torch.long)y_test = torch.tensor(y_test, dtype=torch.long)Definición del Modelo y Optimizadores
Red secuencial con tres capas que reducen gradualmente la dimensionalidad (de 11 a 512, de 512 a 256 y finalmente a 11 posibles salidas), utilizando ReLU como función de activación.
class WineNeuronalNetwork(nn.Module): def __init__(self): super().__init__() self.architecture = nn.Sequential( nn.Linear(11, 512), nn.ReLU(), nn.Linear(512, 256), nn.ReLU(), nn.Linear(256, 11) )
def forward(self, x): r = self.architecture(x) return r
loss_fn = nn.CrossEntropyLoss()learning_rate = 0.1batch_size = 64Ciclo de Entrenamiento y Evaluación
def train_loop(X,y,model,loss_fn,optimizer): size = X.shape[0] model.train() i = 0 total_loss = 0 num_batches = 0 while i < size: Xe = X[i:i+batch_size,:] ye = y[i:i+batch_size]
pred = model(Xe) loss_val = loss_fn(pred,ye)
loss_val.backward() optimizer.step() optimizer.zero_grad()
total_loss += loss_val.item() num_batches += 1
i += batch_size
return total_loss / num_batches
def test_loop(t,X,y,model): model.eval()
with torch.no_grad(): pred = model(X)
size = pred.shape[0] a = torch.argmax(pred,axis=1) b = y correct = (a==b).type(torch.float).sum().item() accuracy = correct / size
print (f"Epoch:{t} - Acc:{accuracy}")Ejecución del Comparativo
Entrenamos cada variante de la red neuronal por 200 épocas. Durante cada iteración por optimizador, guardamos el historial de la pérdida para ser posteriormente visualizado y comparado, y finalmente evaluamos y almacenamos el modelo pre-entrenado para su reutilización.
Recalco que el codigo aqui esta automatizado, pero se hizo una busqueda manual para encontrar el mejor learning rate para cada optimizador.
epochs = 200
optimizadores_a_probar = [ ('Adam', 'loss_adam.txt', 0.01), ('SGD', 'loss_sgd.txt', 0.1), ('SGD Nesterov', 'loss_nesterov.txt', 0.1)]
for nombre_opt, archivo_salida, lr_opt in optimizadores_a_probar:
model_actual = WineNeuronalNetwork()
if nombre_opt == 'Adam': opt_actual = torch.optim.Adam(model_actual.parameters(), lr=lr_opt) elif nombre_opt == 'SGD': opt_actual = torch.optim.SGD(model_actual.parameters(), lr=lr_opt) else: opt_actual = torch.optim.SGD(model_actual.parameters(), lr=lr_opt, momentum=0.9, nesterov=True)
historial_loss = []
for t in range(epochs): avg_loss = train_loop(X_train, y_train, model_actual, loss_fn, opt_actual) historial_loss.append(avg_loss)
print(f"Resultados de {nombre_opt}:") test_loop(epochs, X_test, y_test, model_actual)
np.savetxt(archivo_salida, historial_loss) torch.save(model_actual, f'model_{nombre_opt.replace(" ", "_").lower()}.pth')Gráfica de Perdida vs Epoca
import matplotlib.pyplot as plt, numpy as np, os
pruebas = [('Adam', 'loss_adam.txt', '#E67E22'), ('SGD', 'loss_sgd.txt', '#8E44AD'), ('SGD Nesterov', 'loss_nesterov.txt', '#1ABC9C')]
for nombre, archivo, color in pruebas: if os.path.exists(archivo): plt.plot(np.loadtxt(archivo), label=nombre, color=color, linewidth=2)
plt.title('Pérdida vs Época (15% de datos)')plt.xlabel('Época')plt.ylabel('Pérdida')plt.legend()plt.grid(True)plt.savefig('grafica_loss_final.png')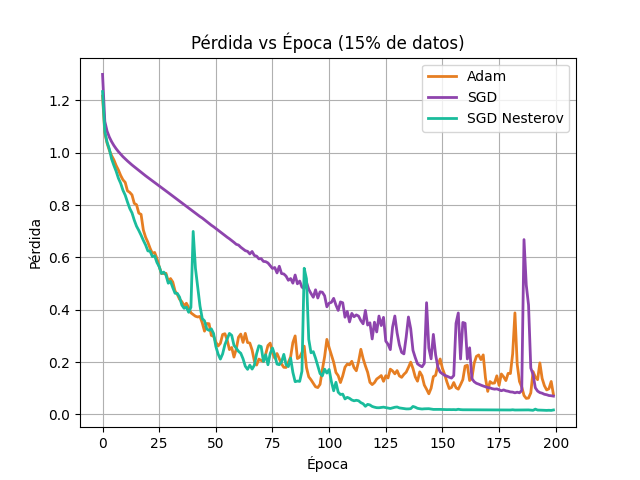
Resultados y Conclusiones
Los mejores resultados de precisión en la validación por optimizador fueron:
- Adam (lr=0.01): 65.57% de precisión.
- SGD (lr=0.1): 66.25% de precisión.
- SGD Nesterov (lr=0.1): 63.40% de precisión.
A pesar de que usualmente se considera que Nesterov acelera la convergencia de manera más agresiva, con los parámetros actuales (momentum de 0.9 y lr de 0.1), el SGD sin momentum produjo una métrica ligeramente superior.
Analizando la gráfica de pérdida, se puede observar que Nesterov disminuye la función objetivo más rápida y suavemente en las etapas iniciales, mientras que Adam tiene oscilaciones.
Estoy seguro que la inestabilidad que muestran los optimizadores se debe al tamaño de la prueba, ya que usé el 15% de los datos para prueba y, aunque está desbalanceado, si hubiera mas datos probablemente convergerian mejor.