Información de la Tarea
Estudiante: Andrés Cruz Chipol
Curso: Arquitectura De Computadoras
Fecha de entrega: 10 de marzo de 2026
Descripción de la Tarea
- Programar el oscilador caótico en el ensamblador del RISC0
- Reportar en simulación que el oscilador esté trabajando
- Probar el programa en el FPGA
- Extraer los datos del FPGA usando la comunicación serial
- Reportar el consumo de recursos del FPGA tanto del diseño anterior como el de esta tarea
Descarga del proyecto
Oscilador caótico de Lü en ensamblador RISC0 sobre FPGA
Introducción
En la tarea anterior el oscilador caótico de Lü se implementó como un diseño Verilog dedicado: un datapath que calculaba las derivadas y el método de Euler en hardware. En esta tarea el mismo sistema se ejecuta como programa en el procesador RISC0: el código está en ensamblador, se carga en la PROM y el núcleo ejecuta instrucción a instrucción, con el mismo comportamiento (integración numérica y envío de X, Y, Z por UART), verificada en simulación y en la FPGA Alchitry Cu.
Paso 1: Algoritmo y programa en ensamblador
Modelo de Lü: ( \dot{x} = y ), ( \dot{y} = z ), ( \dot{z} = -a(x + y + z) + a,k,f(x/k) ), con ( f(u) ) por segmentos (saturación ±2 si ( |u|>1.1 ), rampa ( 10(u\mp 0.9) ) si ( 0.9<|u|\le 1.1 ), cero si ( |u|\le 0.9 )); ( a=0.7 ), ( k=16 ). Se usa punto fijo Q14.18 (el RISC0 no tiene coma flotante): multiplicaciones con corrección a 18 bits (MOVH, ASR, mascarado, LSL/IOR). Integración con ASR 13 (( h_{\mathrm{eff}}=1/8192 )) en lugar de MUL por ( h ). Se transmite por UART 1 de cada 128 iteraciones (submuestreo con AND R14, 127); frame 14 bytes: 0xAA 0x55 + X,Y,Z en 4 bytes cada uno. Binario: python assembler.py lu_oscillator.asm lu_oscillator.bin y copia a program.mem.
Programa completo — lu_oscillator.asm
# =================================================================== ## OSCILADOR CAOTICO DE LU EN ENSAMBLADOR RISC0# FORMATO PUNTO FIJO Q14.18# =================================================================== #
START # INICIALIZACION MOV R0 0 # Base I/O para UART
# Carga de condiciones iniciales (Estado X, Y, Z) # X = 5.0 (5.0 * 2^18 = 1310720 = 0x140000) MOV R1 0 # LOW = 0 MOV R8 0x14 # HIGH = 0x14 LSL R8 R8 16 IOR R1 R1 R8 # R1 = X = 0x140000
# Y = 5.0 MOV R2 0 MOV R8 0x14 LSL R8 R8 16 IOR R2 R2 R8 # R2 = Y = 0x140000
# Z = 0.0 MOV R3 0 # R3 = Z
# LED Counter (Heartbeat) MOV R14 0 # Inicio de contador para el LED
# Constantes del sistema # a = 0.7 -> Q14.18 = 183500 (0x2CCCC) MOV R4 0xCCCC MOV R8 0x02 LSL R8 R8 16 IOR R4 R4 R8 # R4 = a
# h = 0.0001 -> Q14.18 = 26 (0x1A) MOV R5 0x1A # R5 = h (legacy, no usado en Euler optimizado)
# k = 16.0 -> 4194304 (0x400000) MOV R6 0 MOV R8 0x40 LSL R8 R8 16 IOR R6 R6 R8 # R6 = k
# inv_k = 1/16 = 0.0625 -> 16384 (0x4000) MOV R7 0x4000 # R7 = inv_k
IntegrationLoop: # ------------------------------------ # HEARTBEAT LED ADD R14 R14 1 # Incrementar contador ASR R15 R14 19 # Dividir reloj moviendo bits (velocidad visible aprox 1 pulso/s) ST R15 R0 4 # Escribir en IOAddr 4 (Mapeado a los 8 LEDs fisicos)
# ------------------------------------ # 1. Calculo de f_pwl(x/k) # arg = x * inv_k -> u = R9 = R1 * R7 >> 18 # En Q14.18, toda multiplicacion debe recorrerse 18 bits MUL R9 R1 R7 MOVH R10 ASR R9 R9 18 # Dividir entre 2^18 para volver a Q14.18 MOV R11 0x3FFF # Mascara 14 bits inferiores AND R9 R9 R11 LSL R10 R10 14 IOR R9 R9 R10 # R9 = arg (u)
# Evaluacion de intervalos de la f_pwl # lim_b = 1.1 -> 0x46666 MOV R8 0x6666 MOV R10 0x04 LSL R10 R10 16 IOR R8 R8 R10 # R8 = lim_b
# CMP u, lim_b -> SUB R10, u, lim_b SUB R10 R9 R8 BRGT GT_LimB # Si u > lim_b
# neg_lim_b = -1.1 -> 0xFFFB999A MOV R8 0x999A MOV R10 0xFFFB LSL R10 R10 16 IOR R8 R8 R10 # R8 = -1.1
SUB R10 R9 R8 BRLT LT_NegLimB # Si u < -lim_b
# lim_a = 0.9 -> 0x39999 MOV R8 0x9999 MOV R10 0x03 LSL R10 R10 16 IOR R8 R8 R10 # R8 = lim_a
SUB R10 R9 R8 BRGT GT_LimA # Si u > lim_a
# neg_lim_a = -0.9 -> 0xFFFC6667 MOV R8 0x6667 MOV R10 0xFFFC LSL R10 R10 16 IOR R8 R8 R10 # R8 = -0.9
SUB R10 R9 R8 BRLT LT_NegLimA # Si u < -lim_a
# Si no entra a ningun caso, f_pwl = 0 MOV R8 0 BR DonePWL
GT_LimB: # sat = 2.0 -> 0x80000 MOV R8 0 MOV R10 0x08 LSL R10 R10 16 IOR R8 R8 R10 BR DonePWL
LT_NegLimB: # neg_sat = -2.0 -> 0xFFF80000 MOV R8 0 MOV R10 0xFFF8 LSL R10 R10 16 IOR R8 R8 R10 BR DonePWL
GT_LimA: # f_pwl = slope * (u - lim_a) # slope = 10.0 -> 0x280000 MOV R12 0 MOV R11 0x28 LSL R11 R11 16 IOR R12 R12 R11 # R12 = slope MUL R8 R10 R12 # R10 ya tiene (u - lim_a) MOVH R11 ASR R8 R8 18 MOV R13 0x3FFF AND R8 R8 R13 LSL R11 R11 14 IOR R8 R8 R11 # R8 = slope*(u-lim_a) BR DonePWL
LT_NegLimA: # f_pwl = slope * (u + lim_a) MOV R12 0 MOV R11 0x28 LSL R11 R11 16 IOR R12 R12 R11 # R12 = slope MUL R8 R10 R12 # R10 ya tiene (u + lim_a) MOVH R11 ASR R8 R8 18 MOV R13 0x3FFF AND R8 R8 R13 LSL R11 R11 14 IOR R8 R8 R11 # R8 = slope*(u+lim_a)
DonePWL: # ------------------------------------ # R8 contiene ahora f_val. Calculamos 'nonlinear' = a * k * f_val # 1. R10 = k * f_val MUL R10 R8 R6 MOVH R11 ASR R10 R10 18 MOV R12 0x3FFF AND R10 R10 R12 LSL R11 R11 14 IOR R10 R10 R11
# 2. R13 = a * (k * f_val) -> R13 = nonlinear MUL R13 R10 R4 MOVH R11 ASR R13 R13 18 MOV R12 0x3FFF AND R13 R13 R12 LSL R11 R11 14 IOR R13 R13 R11
# ------------------------------------ # d[2] = -a*(X + Y + Z) + nonlinear # 1. Sumar X + Y + Z ADD R8 R1 R2 ADD R8 R8 R3 # R8 = X + Y + Z
# 2. Multiplicar por 'a' MUL R8 R8 R4 MOVH R11 ASR R8 R8 18 MOV R12 0x3FFF AND R8 R8 R12 LSL R11 R11 14 IOR R8 R8 R11 # R8 = a * (X + Y + Z)
# 3. Restarle a nonlinear SUB R13 R13 R8 # R13 = d[2] finalizado
# ------------------------------------ # METODO DE EULER VELOZ (Shift Aritmetico) # Original usaba MUL+MOVH+ASR+AND+LSL+IOR (6 instr.) por cada variable # Nuevo: ASR 13 equivale a h=1/8192, se ejecuta en 1 ciclo de reloj # Original para X era: # MUL R8 R2 R5 / MOVH R11 / ASR R8 R8 18 / MOV R12 0x3FFF / AND R8 R8 R12 / LSL R11 R11 14 / IOR R8 R8 R11
# x_next = x + h * d[0] -> d[0] = Y = R2 ASR R8 R2 13 # R8 = h * Y ADD R1 R1 R8 # X += h * Y
# y_next = y + h * d[1] -> d[1] = Z = R3 ASR R8 R3 13 # R8 = h * Z ADD R2 R2 R8 # Y += h * Z
# z_next = z + h * d[2] -> d[2] = R13 ASR R8 R13 13 # R8 = h * d2 ADD R3 R3 R8 # Z += h * d2
# ------------------------------------ # TRANSMISION UART AL PC HOST MOV R10 127 AND R8 R14 R10 BRGT SkipUART
WaitHdr1: LD R8 R0 16332 MOV R9 2 AND R10 R8 R9 BRGT WaitHdr1 MOV R8 170 ST R8 R0 16328
# Transmitir 0x55 (Header 2)WaitHdr2: LD R8 R0 16332 MOV R9 2 AND R10 R8 R9 BRGT WaitHdr2 MOV R8 85 ST R8 R0 16328
# Transmitir X (R1) del MSB al LSB ASR R8 R1 24 MOV R12 255 AND R8 R8 R12WaitX1: LD R9 R0 16332 MOV R10 2 AND R11 R9 R10 BRGT WaitX1 ST R8 R0 16328
ASR R8 R1 16 MOV R12 255 AND R8 R8 R12WaitX2: LD R9 R0 16332 MOV R10 2 AND R11 R9 R10 BRGT WaitX2 ST R8 R0 16328
ASR R8 R1 8 MOV R12 255 AND R8 R8 R12WaitX3: LD R9 R0 16332 MOV R10 2 AND R11 R9 R10 BRGT WaitX3 ST R8 R0 16328
MOV R12 255 AND R8 R1 R12WaitX4: LD R9 R0 16332 MOV R10 2 AND R11 R9 R10 BRGT WaitX4 ST R8 R0 16328
# Transmitir Y (R2) ASR R8 R2 24 MOV R12 255 AND R8 R8 R12WaitY1: LD R9 R0 16332 MOV R10 2 AND R11 R9 R10 BRGT WaitY1 ST R8 R0 16328
ASR R8 R2 16 MOV R12 255 AND R8 R8 R12WaitY2: LD R9 R0 16332 MOV R10 2 AND R11 R9 R10 BRGT WaitY2 ST R8 R0 16328
ASR R8 R2 8 MOV R12 255 AND R8 R8 R12WaitY3: LD R9 R0 16332 MOV R10 2 AND R11 R9 R10 BRGT WaitY3 ST R8 R0 16328
MOV R12 255 AND R8 R2 R12WaitY4: LD R9 R0 16332 MOV R10 2 AND R11 R9 R10 BRGT WaitY4 ST R8 R0 16328
# Transmitir Z (R3) ASR R8 R3 24 MOV R12 255 AND R8 R8 R12WaitZ1: LD R9 R0 16332 MOV R10 2 AND R11 R9 R10 BRGT WaitZ1 ST R8 R0 16328
ASR R8 R3 16 MOV R12 255 AND R8 R8 R12WaitZ2: LD R9 R0 16332 MOV R10 2 AND R11 R9 R10 BRGT WaitZ2 ST R8 R0 16328
ASR R8 R3 8 MOV R12 255 AND R8 R8 R12WaitZ3: LD R9 R0 16332 MOV R10 2 AND R11 R9 R10 BRGT WaitZ3 ST R8 R0 16328
MOV R12 255 AND R8 R3 R12WaitZ4: LD R9 R0 16332 MOV R10 2 AND R11 R9 R10 BRGT WaitZ4 ST R8 R0 16328
SkipUART: BR IntegrationLoop
ENDPaso 2: Simulación
Objetivo
Comprobar en simulación que el RISC0 ejecuta el programa del oscilador y que por la UART salen las tramas de 14 bytes (0xAA, 0x55 y los 12 bytes de X, Y, Z).
Script de simulación — simular.sh
El script ensambla el código, genera program.mem, compila el testbench con Icarus Verilog (incluyendo RISC0Top, RISC0, memorias, multiplicador, divisor y módulos UART), ejecuta la simulación guardando las formas de onda en micro.vcd y los bytes UART en uart_sim_log.txt, y abre GTKWave con el VCD.
#!/bin/bash# ===================================================================# Script de Simulación y GTKWave - Oscilador de Lü (RISC0)# ===================================================================
set -e
echo "[1/4] Ensamblando el código RISC0 para la simulación..."python assembler.py lu_oscillator.asm lu_oscillator.bincp lu_oscillator.bin program.mem
echo "[2/4] Compilando el banco de pruebas (Icarus Verilog)..."iverilog -o sim_monitor.vvp RISC0Top_tb_monitor.v RISC0Top.v RISC0.v Divider.v DRAM.v Multiplier.v PROM.v uart_rx.v uart_tx.v
echo "[3/4] Ejecutando simulación (generando micro.vcd)..."echo "Nota: Esto simulará unos milisegundos de hardware. Espere por favor..."vvp sim_monitor.vvp > uart_sim_log.txt
echo "[4/4] Abriendo GTKWave..."gtkwave micro.vcd &Banco de pruebas — RISC0Top_tb_monitor.v
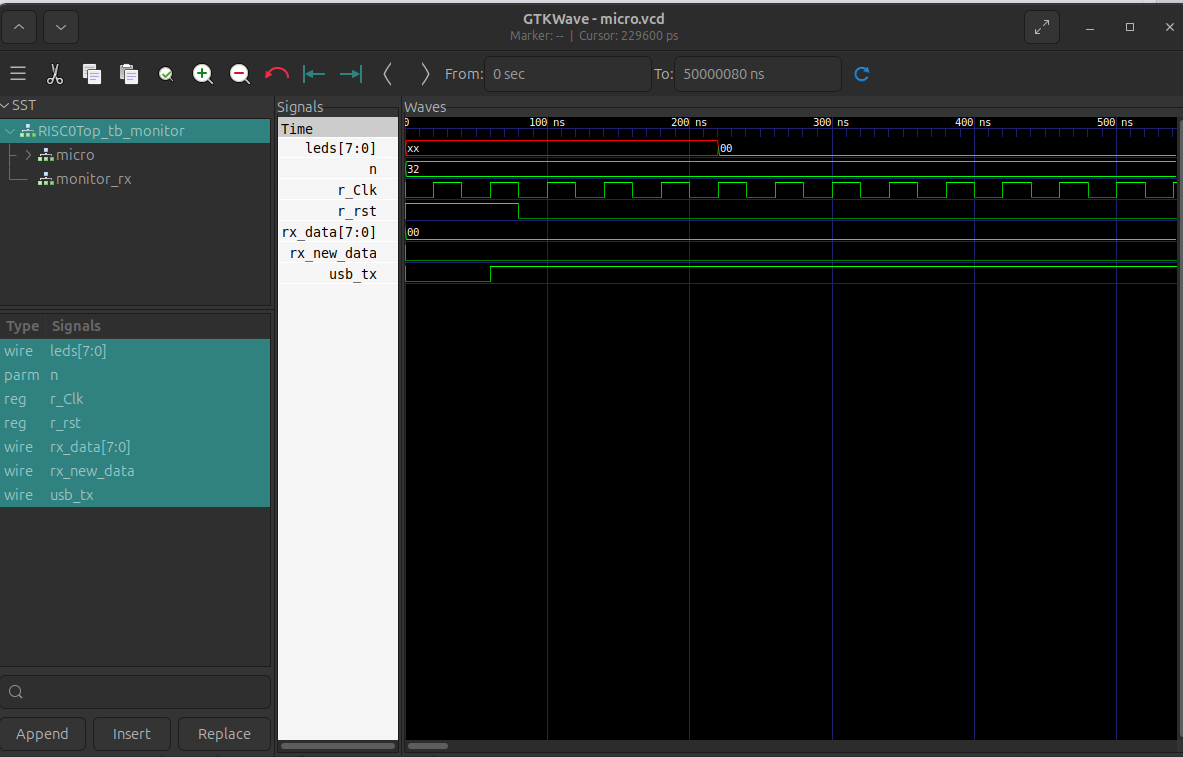
El testbench instancia el sistema completo (RISC0Top con RISC0, PROM, DRAM, UART TX, etc.). La salida TX del diseño se conecta a un receptor UART (uart_rx) que decodifica los bytes; en cada byte recibido se hace $display("UART_BYTE: %02x", rx_data), de modo que en uart_sim_log.txt aparecen las secuencias 0xAA, 0x55 y los doce bytes de X, Y, Z. Eso confirma que el programa integra el sistema y envía las variables. El archivo VCD permite revisar en GTKWave señales como el reloj, el reset, los LEDs y la línea UART.
`timescale 10ns / 1ps
module RISC0Top_tb_monitor ();
localparam n=32;reg r_Clk = 1'b0;reg r_rst = 1'b1;wire usb_rx_dummy; wire usb_tx;wire [7:0] leds;
always #2 r_Clk <= !r_Clk;
RISC0Top micro (.clk(r_Clk),.rst_n(r_rst),.usb_rx(1'b1),.usb_tx(usb_tx),.led(leds) );
wire [7:0] rx_data; wire rx_new_data;
uart_rx monitor_rx( .clk(r_Clk), .rst(~r_rst), .rx(usb_tx), .data(rx_data), .new_data(rx_new_data) );
always @(posedge r_Clk) begin if (rx_new_data) begin $display("UART_BYTE: %02x", rx_data); end end
initial begin $dumpfile("micro.vcd"); $dumpvars(0, RISC0Top_tb_monitor);#8;r_rst <= 1'b0;#5000000;$finish();endendmoduleEjecución y resultado
Desde la carpeta del proyecto se ejecuta ./simular.sh. En uart_sim_log.txt deben verse líneas como UART_BYTE: aa, UART_BYTE: 55 seguidas de los doce bytes de X, Y, Z en hexadecimal, repetidas cada 128 iteraciones del bucle. Con gtkwave micro.vcd se inspeccionan las formas de onda. A continuación, captura de GTKWave mostrando señales de la simulación (reloj, reset, UART TX y LEDs):
Paso 3: Síntesis y prueba en FPGA
Objetivo
Compilar el diseño Verilog (RISC0Top, RISC0, PROM, DRAM, multiplicador, divisor, UART TX/RX y mapeo de E/S) para la FPGA Alchitry Cu (iCE40-HX8K) y programar la placa. La verificación visual se hace con los LEDs: el programa escribe en la dirección de E/S del LED un bit derivado del contador R14 (heartbeat), por lo que los LEDs parpadean mientras el RISC0 está ejecutando el bucle del oscilador.
Script de construcción y subida — build_and_upload.sh
El script ensambla lu_oscillator.asm, copia el binario a program.mem (que la síntesis usa para inicializar la PROM), limpia la caché de Apio, ejecuta apio build (Yosys, nextpnr, icepack) y luego apio upload para flashear el bitstream a la FPGA.
#!/bin/bash# ===================================================================# Script de Construcción y Subida - Oscilador de Lü (RISC0)# ===================================================================
set -e
echo "[1/4] Ensamblando el código RISC0 (lu_oscillator.asm)..."python assembler.py lu_oscillator.asm lu_oscillator.bin
echo "[2/4] Preparando la memoria del procesador (program.mem)..."cp lu_oscillator.bin program.mem
echo "[3/4] Limpiando caché y re-sintetizando la FPGA (apio build)..."# Fuerza reconstruccion completa porque program.mem cambio (lo lee en tiempo de sintesis)apio cleanapio build
echo "[4/4] Flasheando la FPGA (apio upload)..."apio upload
echo "¡Éxito!"Verificación en la placa
Tras apio upload, los 8 LEDs de la Alchitry Cu deben mostrar un parpadeo (heartbeat). Eso indica que el RISC0 está ejecutando el bucle de integración y actualizando el registro de salida hacia el LED; el oscilador está corriendo en el FPGA.
Paso 4: Extracción de datos por comunicación serial
Objetivo
Recibir en el PC las tramas UART que envía el FPGA (cabecera 0xAA 0x55 + X, Y, Z en 4 bytes cada uno, Q14.18 big-endian) y visualizar en tiempo real la serie temporal de X y el plano de fase X-Y.
Configuración UART
| Parámetro | Valor |
|---|---|
| Baud rate | 1 000 000 |
| Formato | 8N1 |
| Frame | 14 bytes: 0xAA 0x55 + X (4) + Y (4) + Z (4) |
El script Python busca el header b'\xaa\x55' en el flujo de bytes, extrae los 12 bytes siguientes, interpreta los primeros 4 como X y los siguientes 4 como Y en Q14.18 (dividiendo por ( 2^{18} ) el entero con signo) y opcionalmente puede usar Z para otras gráficas.
Script de captura y visualización — plot.py
El script abre el puerto serie (por defecto o detectado, p. ej. /dev/ttyUSB1), lee en un hilo secundario, busca tramas de 14 bytes con cabecera 0xAA 0x55, decodifica X e Y con to_fixed (Q14.18 a float) y actualiza buffers para la serie temporal y el plano de fase. La ventana de matplotlib se actualiza cada 50 ms con la serie X(t) y el diagrama X-Y, mostrando el número de puntos recibidos.
import serial, serial.tools.list_ports, threading, collectionsimport matplotlib.pyplot as pltimport matplotlib.animation as animationimport numpy as np
# ----- Config -----BAUD = 1_000_000HEADER = b'\xaa\x55'N_TS = 2000 # ventana serie de tiempoN_XY = 8000 # historia plano de faseDECIMATE = 5OUTLIER = 50.0
def get_port(): for p in serial.tools.list_ports.comports(): if "USB" in p.device or "ttyACM" in p.device: return p.device return "/dev/ttyUSB1"
def to_fixed(b4): return int.from_bytes(b4, 'big', signed=True) / (1 << 18)
# ----- Buffers -----lock = threading.Lock()buf_x = collections.deque(maxlen=N_TS)buf_t = collections.deque(maxlen=N_TS)buf_xx = collections.deque(maxlen=N_XY)buf_yy = collections.deque(maxlen=N_XY)total = [0]skip = [0]
def reader(): try: ser = serial.Serial(get_port(), BAUD, timeout=1) except Exception as e: print(e); return raw = b'' while True: raw += ser.read(64) while len(raw) >= 14: idx = raw.find(HEADER) if idx < 0: raw = raw[-1:]; break if idx + 14 > len(raw): break if idx > 0: raw = raw[idx:]; continue f, raw = raw[:14], raw[14:] skip[0] += 1 if skip[0] % DECIMATE: continue x, y = to_fixed(f[2:6]), to_fixed(f[6:10]) if abs(x) > OUTLIER or abs(y) > OUTLIER: continue total[0] += 1 with lock: buf_t.append(total[0]); buf_x.append(x) buf_xx.append(x); buf_yy.append(y)
threading.Thread(target=reader, daemon=True).start()
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(11, 4))ax1.set_title("Serie de tiempo X"); ax1.set_xlabel("muestra"); ax1.set_ylabel("X")ax2.set_title("Plano de fase X-Y"); ax2.set_xlabel("X"); ax2.set_ylabel("Y")ln1, = ax1.plot([], [], lw=1)ln2, = ax2.plot([], [], lw=0.5)
def update(_): with lock: if len(buf_t) < 2: return t = np.asarray(buf_t); x = np.asarray(buf_x) xx = np.asarray(buf_xx); yy = np.asarray(buf_yy) ln1.set_data(t, x) ax1.set_xlim(t[0], t[-1]); ax1.set_ylim(x.min()-0.5, x.max()+0.5) ln2.set_data(xx, yy) if len(xx): ax2.set_xlim(xx.min()-0.5, xx.max()+0.5) ax2.set_ylim(yy.min()-0.5, yy.max()+0.5) fig.suptitle(f"Oscilador Lü — {total[0]:,} pts")
ani = animation.FuncAnimation(fig, update, interval=50, cache_frame_data=False)plt.tight_layout(); plt.show()Ejecución
Con la FPGA conectada y ya programada: python plot.py (o conda run -n base python plot.py si se usa ese entorno). Si el puerto requiere permisos: sudo chmod 666 /dev/ttyUSB1 (o el dispositivo que corresponda).
Evidencia
Video del funcionamiento en FPGA con captura serial y visualización en tiempo real (serie X y plano de fase X-Y):
Paso 5: Consumo de recursos del FPGA y comparativa
Esta tarea (RISC0 + oscilador en ensamblador):
| Recurso | Usados | Disponibles | Uso (%) |
|---|---|---|---|
| ICESTORM_LC | 3860 | 7680 | 50.3% |
| ICESTORM_RAM | 32 | 32 | 100% |
| SB_IO | 12 | 256 | 4.7% |
| SB_GB (Global) | 8 | 8 | 100% |
Diseño anterior (oscilador en Verilog dedicado):
| Recurso | Usados | Disponibles | Uso (%) |
|---|---|---|---|
| ICESTORM_LC | 3728 | 7680 | 48.5% |
| ICESTORM_RAM | 0 | 32 | 0.0% |
| SB_IO | 11 | 256 | 4.3% |
| SB_GB | 5 | 8 | 62.5% |
RISC0 a 25 MHz. En este diseño se usa toda la RAM de bloque (PROM+DRAM) y los 8 buffers globales; el anterior solo lógica (0% RAM, 62.5% GB). La diferencia corresponde al costo del procesador programable frente al datapath fijo.
Conclusiones
Oscilador de Lü implementado en ensamblador RISC0 (Q14.18, Euler con ASR 13, UART 0xAA 0x55). Verificado en simulación, sintetizado en la FPGA Alchitry Cu y extracción en tiempo real con el script Python. Recursos: 50.3% LUTs, 100% RAM y 100% GB (frente a 48.5% LUTs y 0% RAM del diseño anterior), por el uso del procesador completo.