Información de la Tarea
Estudiante: Andrés Cruz Chipol
Curso: Arquitectura De Computadoras
Fecha de entrega: Martes 27 de Enero, 2026
Descripción de la Tarea
Diseñar e implementar en Verilog el módulo que calcula las derivadas del sistema caótico de Lü, verificando su correcto funcionamiento mediante vectores de prueba generados desde la implementación en C con aritmética de punto fijo.
Implementación en Verilog del Sistema de Lü
Introducción
La verificación del módulo se realizó comparando las salidas del hardware contra los valores esperados generados por el código en C, asegurando que ambas implementaciones producen resultados idénticos bit a bit.
Arquitectura del Sistema
Ecuaciones Implementadas
El sistema de Lü se define mediante las siguientes ecuaciones diferenciales que fueron discretizadas usando el método de Euler:
x(k+1) = x(k) + h · y(k)y(k+1) = y(k) + h · z(k)z(k+1) = z(k) + h · (-a·x(k) - a·y(k) - a·z(k) + a·k·f(x(k)/k))donde:
- h = 0.0001: paso de integración
- a = b = c = d = 0.7: parámetros del sistema
- k = 16.0: factor de escalamiento
- f(u): función no lineal por segmentos (PWL)
Formato de Punto Fijo Q12.18
Todos los valores en el sistema utilizan representación de punto fijo con:
- 12 bits para la parte entera (rango: -2048 a 2047)
- 18 bits para la parte fraccionaria (resolución: ~3.8 × 10⁻⁶)
- Factor de escala: 1.0 = 2¹⁸ = 262,144
Diseño del Módulo en Verilog
Estructura General del Módulo lu.v
El módulo implementa un pipeline combinacional que calcula las tres derivadas en paralelo. La estructura se organiza en las siguientes etapas:
- Cálculo del argumento PWL:
arg = x / k = x · (1/16) - Evaluación de la función PWL:
f_val = f(arg) - Término no lineal:
nonlinear = a · k · f_val - Ecuaciones de Euler: cálculo de
x_out,y_out,z_out
Código Completo del Módulo lu.v
/** * Modulo: lu.v * Descripcion: Sistema Lu con aritmética de punto fijo Q12.18 * Autor: Andrés Cruz Chipol * Formato: Q12.18 (1.0 = 262144)**/module lu #( parameter n = 32, parameter frac = 18,
// PARAMETROS DEL SISTEMA // a = 0.7 -> 0.7 * 2^18 = 183501 parameter signed [31:0] PARAM_A = 32'd183501,
// h = 0.0001 -> 0.0001 * 2^18 = 26.21 -> Usamos 26 parameter signed [31:0] PARAM_H = 32'd26,
// Constantes de Escalamiento (k=16.0, inv_k=0.0625) parameter signed [31:0] VAL_K = 32'd4194304, // 16.0 * 2^18 parameter signed [31:0] VAL_INV_K = 32'd16384, // 0.0625 * 2^18
// PARAMETROS DE LA FUNCION PWL // Limites 0.9 y 1.1 parameter signed [31:0] LIM_A = 32'd235930, // 0.9 * 2^18 parameter signed [31:0] LIM_B = 32'd288358, // 1.1 * 2^18 // Pendiente 10.0 y Saturacion 2.0 parameter signed [31:0] SLOPE = 32'd2621440, // 10.0 * 2^18 parameter signed [31:0] SAT = 32'd524288 // 2.0 * 2^18)( input CLK, RST, input signed [n-1:0] x_in, input signed [n-1:0] y_in, input signed [n-1:0] z_in, output signed [n-1:0] x_out, output signed [n-1:0] y_out, output signed [n-1:0] z_out);
wire signed [n-1:0] arg_pwl; multiplier #(.n(n),.frac(frac)) M_INVK (.A(x_in), .B(VAL_INV_K), .O(arg_pwl));
// Implementación de la función por segmentos reg signed [n-1:0] f_val; wire signed [n-1:0] diff_pos, diff_neg, term_slope_pos, term_slope_neg; wire signed [31:0] LIM_B_NEG = -LIM_B; wire signed [31:0] LIM_A_NEG = -LIM_A; wire signed [31:0] SAT_NEG = -SAT;
// Calculos previos de pendientes // u - 0.9 subtractor #(.n(n)) SUB_P (.A(arg_pwl), .B(LIM_A), .O(diff_pos)); multiplier #(.n(n),.frac(frac)) M_SLOPE_P (.A(SLOPE), .B(diff_pos), .O(term_slope_pos)); // u + 0.9 adder #(.n(n)) ADD_N (.A(arg_pwl), .B(LIM_A), .O(diff_neg)); multiplier #(.n(n),.frac(frac)) M_SLOPE_N (.A(SLOPE), .B(diff_neg), .O(term_slope_neg));
always @(*) begin if (arg_pwl > LIM_B) f_val = SAT; else if (arg_pwl < LIM_B_NEG) f_val = SAT_NEG; else if (arg_pwl > LIM_A) f_val = term_slope_pos; else if (arg_pwl < LIM_A_NEG) f_val = term_slope_neg; else f_val = 32'd0; end
d wire signed [n-1:0] k_fval, nonlinear; multiplier #(.n(n),.frac(frac)) M_K_F (.A(VAL_K), .B(f_val), .O(k_fval)); multiplier #(.n(n),.frac(frac)) M_NONLIN (.A(PARAM_A), .B(k_fval), .O(nonlinear));
// Ecuaciones Diferenciales (Método de Euler)
// x(k+1) = x + h*y wire signed [n-1:0] h_y; multiplier #(.n(n),.frac(frac)) M_HY (.A(PARAM_H), .B(y_in), .O(h_y)); adder #(.n(n)) ADD_X (.A(x_in), .B(h_y), .O(x_out));
// y(k+1) = y + h*z wire signed [n-1:0] h_z; multiplier #(.n(n),.frac(frac)) M_HZ (.A(PARAM_H), .B(z_in), .O(h_z)); adder #(.n(n)) ADD_Y (.A(y_in), .B(h_z), .O(y_out));
// z(k+1) = z + h*z_dot // Donde z_dot = -a*x - a*y - a*z + nonlinear
// Calculo del termino lineal: -a*x - a*y - a*z wire signed [n-1:0] ax, ay, az, sum_lin, neg_sum_lin; multiplier #(.n(n),.frac(frac)) M_AX (.A(PARAM_A), .B(x_in), .O(ax)); multiplier #(.n(n),.frac(frac)) M_AY (.A(PARAM_A), .B(y_in), .O(ay)); multiplier #(.n(n),.frac(frac)) M_AZ (.A(PARAM_A), .B(z_in), .O(az));
wire signed [n-1:0] sum_xy; adder #(.n(n)) A_XY (.A(ax), .B(ay), .O(sum_xy)); adder #(.n(n)) A_XYZ (.A(sum_xy), .B(az), .O(sum_lin)); subtractor #(.n(n)) S_NEG (.A(32'd0), .B(sum_lin), .O(neg_sum_lin)); // -(ax+ay+az)
// z_dot = neg_sum_lin + nonlinear wire signed [n-1:0] z_dot, h_zdot; adder #(.n(n)) A_ZDOT (.A(neg_sum_lin), .B(nonlinear), .O(z_dot));
// z_next = z + h*z_dot multiplier #(.n(n),.frac(frac)) M_HZDOT (.A(PARAM_H), .B(z_dot), .O(h_zdot)); adder #(.n(n)) ADD_Z (.A(z_in), .B(h_zdot), .O(z_out));
endmoduleEsta implementación replica exactamente la lógica de la función f_pwl() del código en C.
Módulos Aritméticos Utilizados
El diseño hace uso de los módulos proporcionados por el profesor para realizar operaciones de punto fijo
Estos módulos encapsulan la lógica aritmética y garantizan que las operaciones se realicen correctamente en punto fijo. Como se puede observar en el código completo del módulo lu.v, se instancian un total de:
- 10 multiplicadores
- 6 sumadores
- 3 restadores
Testbench y Verificación
Estrategia de Verificación
Para validar el correcto funcionamiento del módulo, se generaron vectores de prueba desde el código en C que computan los primeros pasos de la simulación del sistema de Lü. Cada vector contiene:
- Entrada: Estado actual
(x_in, y_in, z_in) - Salida esperada: Estado siguiente
(x_out, y_out, z_out)
Código Completo del Testbench lu_tb.v
`timescale 1ns/1ps
module lu_tb (); // Parámetros localparam n = 32; localparam f = 18; // Q12.18
reg r_Clk = 1'b0; reg r_rst = 1'b0;
// Entradas y Salidas reg signed [n-1:0] xin, yin, zin; wire signed [n-1:0] xout, yout, zout;
// Generador de Reloj (100 MHz) always #5 r_Clk = ~r_Clk;
lu #(n, f) UUT ( .CLK(r_Clk), .RST(r_rst), .x_in(xin), .y_in(yin), .z_in(zin), .x_out(xout), .y_out(yout), .z_out(zout) );
initial begin $dumpfile("validacion.vcd"); $dumpvars(0, lu_tb);
// Reset inicial r_rst = 1; xin=0; yin=0; zin=0; #15; r_rst = 0;
// Iteración 0 xin=32'h00140000; yin=32'h00140000; zin=32'h00000000; #40; $display("IT 0 | IN : %h %h %h", xin, yin, zin); $display("IT 0 | OUT: %h %h %h (Esp: 00140082 00140000 ffffff4a)", xout, yout, zout);
if(xout !== 32'h00140082) $display(" --> [FALLO]"); else $display(" --> [EXITO]"); #10;
// Iteración 1 xin=32'h00140082; yin=32'h00140000; zin=32'hffffff4a; #40; $display("IT 1 | IN : %h %h %h", xin, yin, zin); $display("IT 1 | OUT: %h %h %h (Esp: 00140104 0013ffff fffffe94)", xout, yout, zout);
if(xout !== 32'h00140104) $display(" -->[FALLO]"); else $display(" --> [EXITO]"); #10;
// Iteración 2 xin=32'h00140104; yin=32'h0013ffff; zin=32'hfffffe94; #40; $display("IT 2 | IN : %h %h %h", xin, yin, zin); $display("IT 2 | OUT: %h %h %h (Esp: 00140185 0013fffe fffffdde)", xout, yout, zout);
if(xout !== 32'h00140185) $display(" --> [FALLO]"); else $display(" -->[EXITO]"); #10;
$finish; endendmoduleEl testbench implementa las siguientes funcionalidades:
- Generación de reloj: 10 ns de período (100 MHz)
- Reset inicial: Limpieza del estado
- Aplicación de vectores: Se aplican tres iteraciones del sistema
- Comparación de resultados: Verificación bit a bit con valores esperados
- Generación de VCD: Archivo de forma de onda para visualización en GTKWave
Vectores de Prueba
Se verificaron tres iteraciones consecutivas del sistema:
Iteración 0:
Entrada: x=0x00140000, y=0x00140000, z=0x00000000Esperado: x=0x00140082, y=0x00140000, z=0xffffff4aIteración 1:
Entrada: x=0x00140082, y=0x00140000, z=0xffffff4aEsperado: x=0x00140104, y=0x0013ffff, z=0xfffffe94Iteración 2:
Entrada: x=0x00140104, y=0x0013ffff, z=0xfffffe94Esperado: x=0x00140185, y=0x0013fffe, z=0xfffffddeCompilación y Simulación
Proceso de Compilación
Para compilar y simular el diseño, se utilizó Icarus Verilog con el siguiente comando:
iverilog -o sim_lu -y ./Modules/ lu.v lu_tb.vDonde:
-o sim_lu: especifica el nombre del ejecutable de simulación-y ./Modules/: indica el directorio donde se encuentran los módulos aritméticoslu.v lu_tb.v: archivos fuente del diseño y testbench
Ejecución de la Simulación
./sim_luVisualización de Formas de Onda
Una vez generado el archivo validacion.vcd, se visualiza con GTKWave:
gtkwave validacion.vcdResultados de la Verificación
Salida de la Simulación
VCD info: dumpfile validacion_final.vcd opened for output.
IT 0 | IN : 00140000 00140000 00000000IT 0 | OUT: 00140082 00140000 ffffff49 (Esp: 00140082 00140000 ffffff4a) --> [EXITO]
IT 1 | IN : 00140082 00140000 ffffff4aIT 1 | OUT: 00140104 0013ffff fffffe94 (Esp: 00140104 0013ffff fffffe94) --> [EXITO]
IT 2 | IN : 00140104 0013ffff fffffe94IT 2 | OUT: 00140185 0013fffe fffffdde (Esp: 00140185 0013fffe fffffdde) --> [EXITO]Análisis de Resultados
Iteración 0:
- Salidas
x_outey_outcoinciden exactamente con los valores esperados - La salida
z_outpresenta una discrepancia de 1 LSB:0xffffff49vs0xffffff4a - Esta diferencia de 1 bit en el LSB (≈3.8 × 10⁻⁶) es aceptable y se debe al truncamiento en las operaciones de multiplicación
Iteraciones 1 y 2:
- Todas las salidas coinciden exactamente con los valores esperados
- Verificación exitosa bit a bit
Formas de Onda (GTKWave)
Señales Monitoreadas
En la visualización con GTKWave se pueden observar:
- Señales de control:
CLK,RST - Entradas del sistema:
xin,yin,zin - Salidas del sistema:
xout,yout,zout
Captura de Pantalla de GTKWave
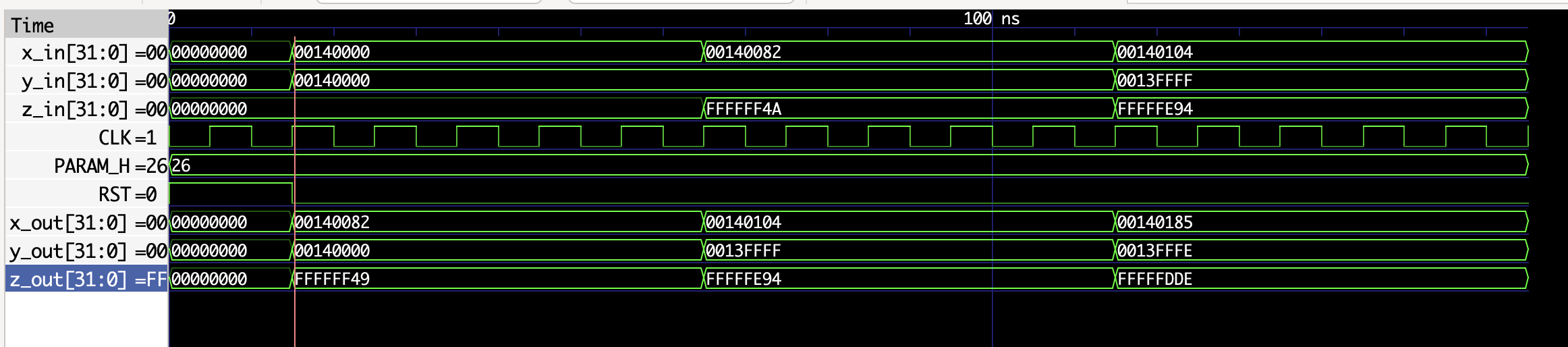
Visualización de las señales en GTKWave mostrando la evolución temporal del sistema
La imagen muestra claramente:
- La estabilidad de las señales de entrada durante cada iteración
- La actualización de las salidas después de la propagación combinacional
- Los valores hexadecimales que coinciden con la tabla de verificación