
Información de la Tarea
Estudiante: Andrés Cruz Chipol
Curso: Aprendizaje Automático
Fecha de entrega: 22 de Abril, 2026
Descripción de la Tarea
Fecha de entrega 22.04.2026
- Utilizaremos imágenes de formas geométricas impresas en papel.(Circulos en mi caso)
- Imprimr las formas en dos o tres hojas de paper en impresora láser. Las hojas de papel deben contener todos el tamaño de la imagen.
- Tomar varias fotografías para realizar la toma de datos
- Se debe realizar un programa en python que reconosca a cada figura que se ve en la imagen tomada por la cámara.
- Usen el clasificador ingenuo de Bayes
Captura de datos
Se tomaron 8 fotografías en diferentes ángulos, distancias e iluminaciones para evitar que el modelo memorice condiciones específicas de captura.







Cada imagen contiene varias figuras dibujadas en la misma hoja. El pipeline de extracción nos permite visualizar los objetdos detectados e ir asignandoles una etiqueta “manualmente”.
Extracción de características
Este script hace el trabajo más delicado: tomar cada imagen, aislar la hoja blanca del fondo, segmentar las figuras y calcular un vector de características geométricas por cada una. Al terminar de procesar una figura, la muestra en pantalla y espera que el usuario presione una tecla para asignarle una etiqueta.
Características extraídas
| Característica | Descripción |
|---|---|
Area | Número de píxeles de la figura |
Log_Area | log(1 + Area) — estabiliza la escala para figuras muy distintas en tamaño |
Compacidad | (4π·Area) / Perímetro² — valor cercano a 1 indican formas circulares |
Solidez | Area / AreaConvexHull — penaliza figuras con concavidades o “mordidas” |
Aspect_Ratio | Proporción ancho/alto del bounding box |
Hu1–Hu7 | Momentos de Hu transformados en escala logarítmica (invariantes a rotación y escala) |
import sys, os, cv2, numpy as np, pandas as pd, glob, math
IMG_DIR = "Tarea8ML_2"OUTPUT_CSV = "data.csv"MARGEN_HOJA = 5AREA_MIN_FIGURA = 200
def calculate_hu_moments_log(moments): """Momentos de Hu con transformación logarítmica para mayor estabilidad.""" hu = cv2.HuMoments(moments).flatten() for i in range(7): if hu[i] != 0: hu[i] = -1 * math.copysign(1.0, hu[i]) * math.log10(abs(hu[i])) return hu
def procesar_imagen(ruta_imagen): img_color = cv2.imread(ruta_imagen) gray = cv2.cvtColor(img_color, cv2.COLOR_BGR2GRAY) blurred = cv2.GaussianBlur(gray, (7, 7), 0)
# Aislar la hoja blanca del fondo oscuro _, thresh_fondo = cv2.threshold(blurred, 130, 255, cv2.THRESH_BINARY) contornos, _ = cv2.findContours(thresh_fondo, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) contorno_hoja = max(contornos, key=cv2.contourArea) x_h, y_h, w_h, h_h = cv2.boundingRect(contorno_hoja) x_h, y_h = x_h + MARGEN_HOJA, y_h + MARGEN_HOJA w_h, h_h = w_h - 2*MARGEN_HOJA, h_h - 2*MARGEN_HOJA recorte_papel = gray[y_h:y_h+h_h, x_h:x_h+w_h]
# Binarizar con Otsu + apertura morfológica para limpiar ruido ret, binarizada = cv2.threshold(recorte_papel, 0, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU) element = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3)) binarizada = cv2.morphologyEx(binarizada, cv2.MORPH_OPEN, element, iterations=2)
num, Etiquetas, stats, _ = cv2.connectedComponentsWithStats(binarizada, 8, cv2.CV_32S) rens, cols = binarizada.shape extracted_data = []
for i in range(1, num): area = stats[i, cv2.CC_STAT_AREA] if not (AREA_MIN_FIGURA < area < rens * cols * 0.5): continue
figura_mask = np.zeros((rens, cols), dtype="uint8") figura_mask[Etiquetas == i] = 255 moments = cv2.moments(figura_mask) hu = calculate_hu_moments_log(moments)
contours_fig, _ = cv2.findContours(figura_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) cnt = contours_fig[0] perimeter = cv2.arcLength(cnt, True) compactness = (4 * math.pi * area) / (perimeter**2) if perimeter > 0 else 0 hull = cv2.convexHull(cnt) solidity = float(area) / cv2.contourArea(hull) if cv2.contourArea(hull) > 0 else 0 w_f = stats[i, cv2.CC_STAT_WIDTH] h_f = stats[i, cv2.CC_STAT_HEIGHT] aspect_ratio = float(w_f) / h_f if h_f > 0 else 0
# Mostrar figura y esperar etiqueta manual x_f, y_f = stats[i, cv2.CC_STAT_LEFT], stats[i, cv2.CC_STAT_TOP] vista = figura_mask[y_f:y_f+h_f, x_f:x_f+w_f] cv2.imshow("Etiquetado - [p]Peq [g]Gra [u]Uni [n]Nada [q]Salir", cv2.resize(vista, (w_f*4, h_f*4), interpolation=cv2.INTER_NEAREST))
while True: key = cv2.waitKey(0) & 0xFF if key == ord('p'): clase = "circuloPequeno"; break elif key == ord('g'): clase = "CirculoGrande"; break elif key == ord('u'): clase = "CirculosUnidos"; break elif key == ord('n'): clase = "ninguno"; break elif key == ord('q'): return extracted_data, True
cv2.destroyAllWindows() if clase != "ninguno": extracted_data.append({ 'Clase': clase, 'Area': area, 'Log_Area': math.log1p(area), 'Compacidad': compactness, 'Solidez': solidity, 'Aspect_Ratio': aspect_ratio, 'Hu1': hu[0], 'Hu2': hu[1], 'Hu3': hu[2], 'Hu4': hu[3], 'Hu5': hu[4], 'Hu6': hu[5], 'Hu7': hu[6] })
return extracted_data, FalseAnálisis exploratorio
El script genera dos tipos de gráficas automáticamente para todas las características del CSV: un stripplot (distribución 1D por clase) y curvas de densidad KDE.
import pandas as pd, matplotlib.pyplot as plt, seaborn as sns, math
df = pd.read_csv('data.csv')features_all = [c for c in df.columns if c not in ['image_file', 'shape_id', 'Clase']]cols, rows = 4, math.ceil(len(features_all) / 4)
# Stripplot — distribución puntual por clasefig, axes = plt.subplots(rows, cols, figsize=(5*cols, 4*rows))for i, feat in enumerate(features_all): sns.stripplot(data=df, x=feat, y='Clase', hue='Clase', ax=axes.flatten()[i], jitter=0.2, palette='Set1', alpha=0.6, size=4) axes.flatten()[i].set_title(feat, fontweight='bold')plt.savefig('scatter_comportamiento_todas.png', dpi=150)
# KDE — densidad de probabilidad por clasefig2, axes2 = plt.subplots(rows, cols, figsize=(5*cols, 4*rows))for i, feat in enumerate(features_all): sns.kdeplot(data=df, x=feat, hue='Clase', ax=axes2.flatten()[i], fill=True, common_norm=False, palette='Set1', alpha=0.5)plt.savefig('distribuciones_completas_kde.png', dpi=150)Distribución por característica (stripplot)
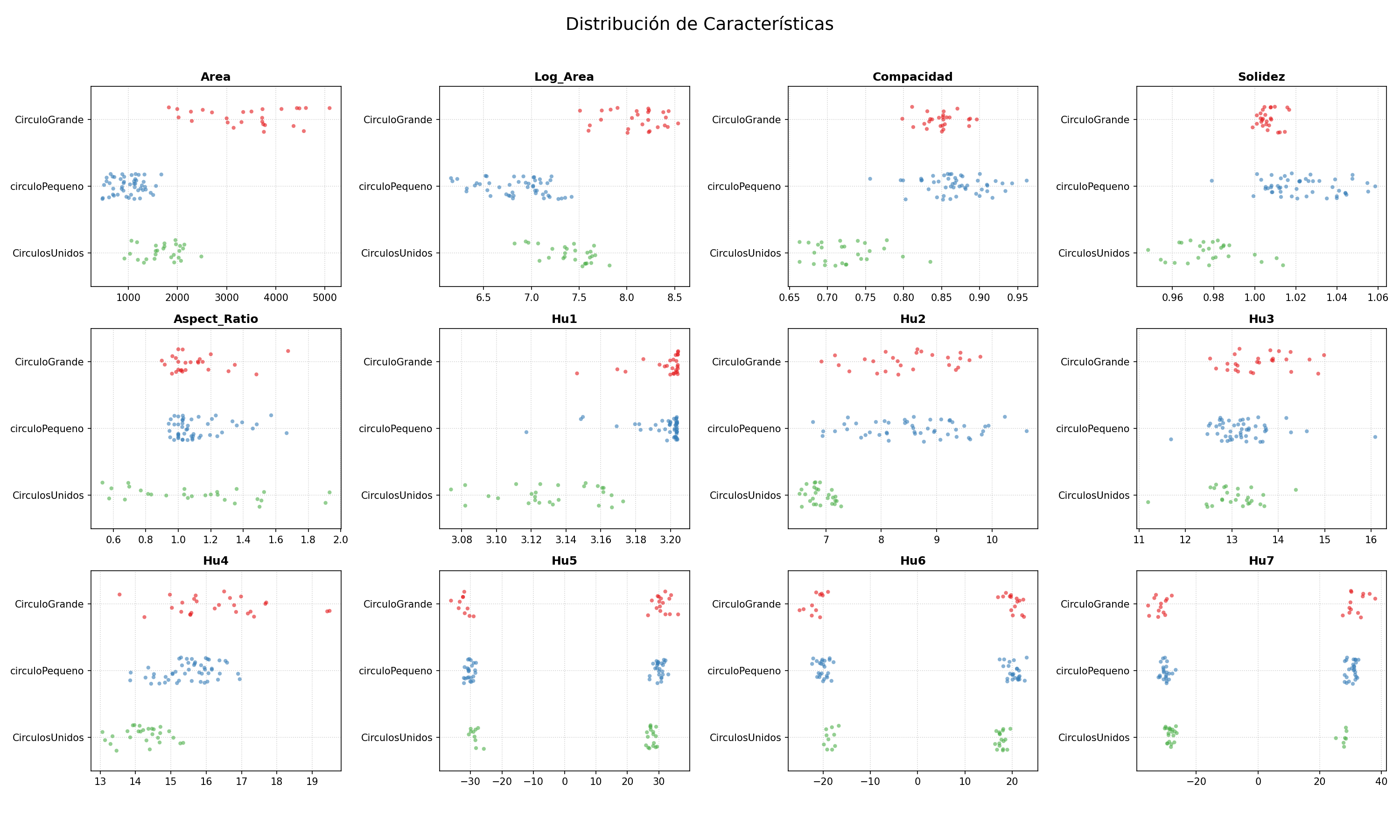
Densidades de probabilidad (KDE)
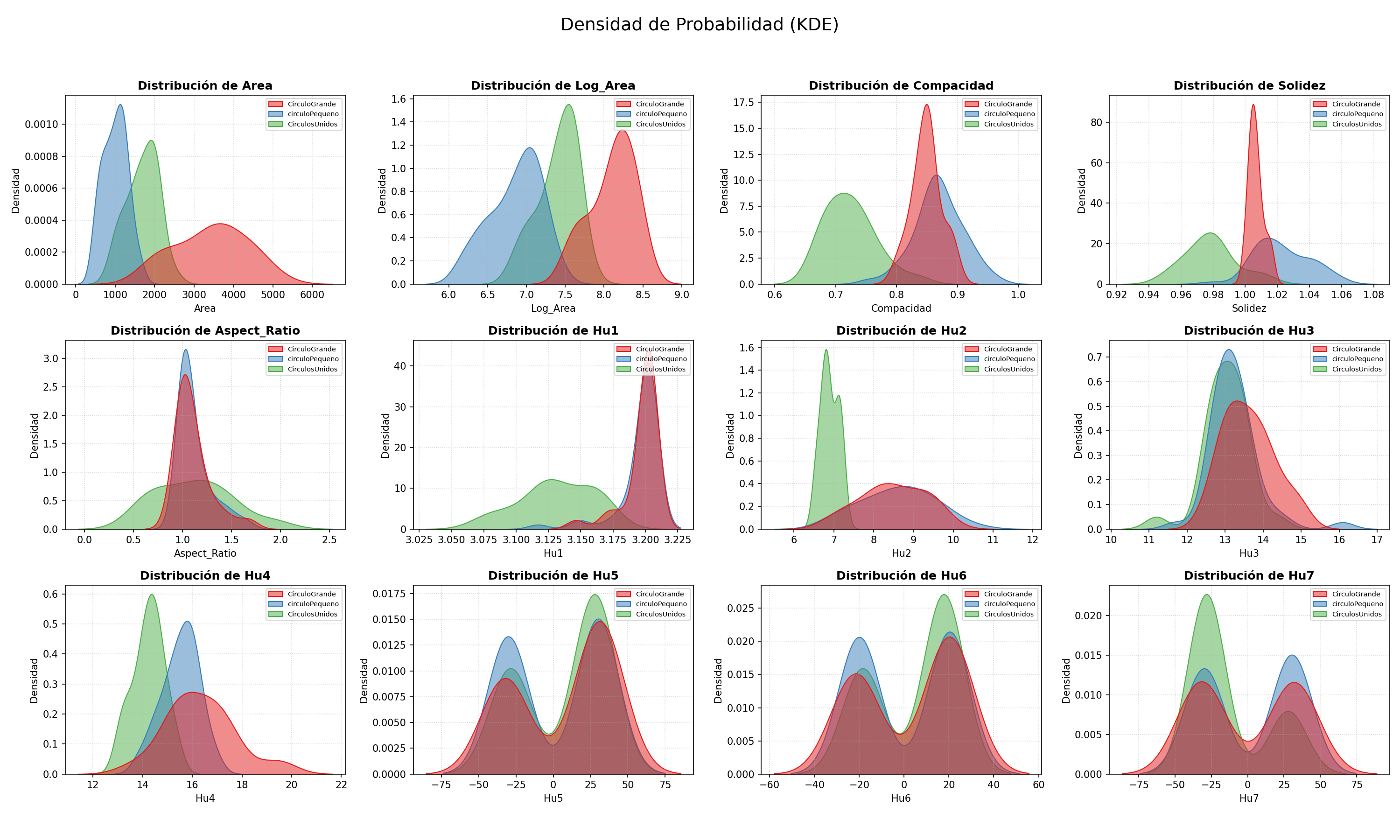
Las gráficas muestran por qué Log_Area, Compacidad y Solidez son las características más informativas: sus distribuciones por clase se separan visualmente de forma clara. Los momentos de Hu individuales se solapan demasiado, aun asi, para llegar a esta conclusion intentamos entrenar con los momentos de Hu, lo cual nos dio resultados menos esperados, por lo que nos centramos en los datos menos solapados. que resulto en un mejor entrenamiento.
Entrenamiento del clasificador Bayesiano
Con los datos analizados, el entrenamiento usa las tres características que mejor separan las clases: Solidez, Compacidad y Log_Area. Se aplica GaussianNB de scikit-learn balanceado los datos.
import pandas as pd, numpy as npfrom sklearn.model_selection import train_test_split, StratifiedKFold, cross_val_scorefrom sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import accuracy_score, classification_report, confusion_matrix
df = pd.read_csv('data.csv')
# Under-sampling para clases balanceadasmin_samples = df['Clase'].value_counts().min()df_balanced = df.groupby('Clase').sample(n=min_samples, random_state=42).reset_index(drop=True)
features = ['Solidez', 'Compacidad', 'Log_Area']X = df_balanced[features].valuesy = df_balanced['Clase'].values
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.3, random_state=42, stratify=y)
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)classifier = GaussianNB(var_smoothing=1e-06)cv_scores = cross_val_score(classifier, X, y, cv=cv)classifier.fit(X_train, y_train)Resultados de entrenamiento
Precisión Validación Cruzada (CV): 91.00%Exactitud en Entrenamiento : 94.44%Exactitud en Prueba : 95.83%Reporte de clasificación (conjunto de prueba)
precision recall f1-score support
CirculoGrande 1.00 1.00 1.00 8CirculosUnidos 1.00 0.88 0.93 8circuloPequeno 0.89 1.00 0.94 8
accuracy 0.96 24 macro avg 0.96 0.96 0.96 24 weighted avg 0.96 0.96 0.96 24Matriz de confusión
| CirculoGrande | CirculosUnidos | circuloPequeno | |
|---|---|---|---|
| CirculoGrande | 8 | 0 | 0 |
| CirculosUnidos | 0 | 7 | 1 |
| circuloPequeno | 0 | 0 | 8 |
El único error ocurre en la clase CirculosUnidos: una muestra queda clasificada como circuloPequeno. Algo que hace sentido ya que los circulos unidos son muy pequeños.
Despues de varios intentos, este fue el mejor clasificador que pudimos alcanzar de acuerdo a las caracteristicas que nos daban las imagenes.
El clasificador Bayesiano manual
El clasificador calcula el log-posterior para cada clase usando la fórmula de verosimilitud gaussiana:
$$\log P(C_k | x) \propto \log P(C_k) + \sum_{j} \left[ -\frac{(x_j - \mu_{kj})^2}{2\sigma_{kj}^2} \right]$$
import numpy as np
clases_nombres = ['CirculoGrande', 'CirculosUnidos', 'circuloPequeno']
pys = np.array([0.3333, 0.3333, 0.3333])lpys = np.log(pys)
# Varianzas estimadas por clase: [Solidez, Compacidad, Log_Area]var = np.array([ [2.19e-05, 5.23e-04, 9.15e-02], # CirculoGrande [1.89e-04, 1.42e-03, 6.85e-02], # CirculosUnidos [3.10e-04, 2.41e-03, 8.63e-02], # circuloPequeno])
# Medias estimadas por clase: [Solidez, Compacidad, Log_Area]med = np.array([ [1.0063, 0.8475, 8.1125], # CirculoGrande [0.9777, 0.7174, 7.3617], # CirculosUnidos [1.0203, 0.8680, 6.8732], # circuloPequeno])
def evalua(x): """Log-posterior para cada clase dado el vector de features x.""" prob = lpys.copy() for i in range(len(clases_nombres)): for j in range(len(x)): e = x[j] - med[i][j] prob[i] -= (e * e) / (2 * var[i][j]) return prob
def predecir(x): return clases_nombres[np.argmax(evalua(x))]
def predecir_prob(x): log_probs = evalua(x) exp_probs = np.exp(log_probs - np.max(log_probs)) return exp_probs / exp_probs.sum()Predicción en tiempo real
El cierre del pipeline es un módulo de detección en vivo. Abre la webcam, aplica exactamente el mismo preprocesamiento que el script de extracción y llama a clasificador.predecir() frame a frame.
import cv2, math, numpy as npimport modelo_bayesian_manual as clasificador
MARGEN_HOJA = 5AREA_MIN_FIGURA = 200
cap = cv2.VideoCapture(0)cap.set(cv2.CAP_PROP_FRAME_WIDTH, 1280)cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 720)
while True: ret, frame = cap.read() gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) blurred = cv2.GaussianBlur(gray, (7, 7), 0) _, thresh_fondo = cv2.threshold(blurred, 130, 255, cv2.THRESH_BINARY) contornos_h, _ = cv2.findContours(thresh_fondo, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
if contornos_h: contorno_hoja = max(contornos_h, key=cv2.contourArea) if cv2.contourArea(contorno_hoja) > 10000: x_h, y_h, w_h, h_h = cv2.boundingRect(contorno_hoja) x_m, y_m = x_h + MARGEN_HOJA, y_h + MARGEN_HOJA w_m, h_m = w_h - 2*MARGEN_HOJA, h_h - 2*MARGEN_HOJA
roi_gray = gray[y_m:y_m+h_m, x_m:x_m+w_m] roi_color = frame[y_m:y_m+h_m, x_m:x_m+w_m]
_, binarizada = cv2.threshold(roi_gray, 0, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU) kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3)) binarizada = cv2.morphologyEx(binarizada, cv2.MORPH_OPEN, kernel, iterations=2) contours, _ = cv2.findContours(binarizada, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for contour in contours: area = cv2.contourArea(contour) if area < AREA_MIN_FIGURA: continue perimeter = cv2.arcLength(contour, True) if perimeter == 0: continue
log_area = math.log1p(area) compactness = (4 * math.pi * area) / (perimeter**2) hull_area = cv2.contourArea(cv2.convexHull(contour)) solidity = area / hull_area if hull_area > 0 else 0
prediccion = clasificador.predecir([solidity, compactness, log_area])
color = { 'CirculoGrande': (255, 0, 0), 'CirculosUnidos': (0, 0, 255), 'circuloPequeno': (0, 255, 255), }.get(prediccion, (0, 255, 0))
x, y, w, h = cv2.boundingRect(contour) cv2.rectangle(roi_color, (x, y), (x+w, y+h), color, 2) cv2.putText(roi_color, prediccion, (x, y-5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 1)
cv2.imshow("Live Bayesian Vision", frame) if cv2.waitKey(1) & 0xFF == ord('q'): break
cap.release()cv2.destroyAllWindows()| Clase | Color |
|---|---|
CirculoGrande | Azul |
CirculosUnidos | Rojo |
circuloPequeno | Cian |
Demostración en video
Conclusiones
Hemos construido un dataset propio, entrenado un clasificador Naive Bayes Gaussiano y lo hemos puesto a prueba en tiempo real. El clasificador alcanzó un 95.83% de exactitud en el conjunto de prueba y demostró funcionar correctamente en tiempo real,con algunos errores en la clasificación de los círculos unidos muy pequeños por cuestiones de las caracteristica.
Tambien en tiempo real vimos que afectan ciertos factores comom la iluminacion, la distancia a la que se encuentra la camara y el angulo de vision.
Esta tarea cierra perfectamente el ciclo de vida de un proyecto de machine learning, desde la recoleccion de datos hasta la implementacion en tiempo real.
Se concluye este curso preparandonos para abordar problemas mas complejos en el proximo curso Aprendizaje Profundo.