
Información de la Tarea
Estudiante: Andrés Cruz Chipol Curso: Aprendizaje Automático Fecha de entrega: Jueves 26 de febrero, 2026
Descripción de la Tarea
Se trabaja con un conjunto de datos donde, a partir de variables clínicas y valores en sangre (edad, sexo, presión arterial, colesterol, sodio Na y potasio K), un médico asigna uno de cuatro medicamentos (A, B, C o D). Con estos datos se debe contestar las preguntas siguientes y cumplir los requisitos de entrega.
Preguntas a contestar
- ¿Cuál fue el razonamiento del médico para recetar cada medicina?
- ¿Se puede ver la relación entre los valores en sangre y la medicina que el médico recetó?
Requisitos de entrega
- Usar validación cruzada.
- Visualizar el mejor árbol.
- Reportar la importancia de las características.
- Usar las tres características más importantes, reentrenar el clasificador y comparar su rendimiento con el obtenido usando todas las características.
Datos y preprocesamiento
El dataset contiene 20 registros con las variables: age, sex, BP (presión arterial: low, normal, high), cholesterol (normal, high), Na (sodio), K (potasio) y la clase drug (A, B, C o D). Código de datos y preprocesamiento:
data.py
data = [ {'age': 33, 'sex': 'F', 'BP': 'high', 'cholesterol': 'high', 'Na': 0.66, 'K': 0.06, 'drug': 'A'}, {'age': 77, 'sex': 'F', 'BP': 'high', 'cholesterol': 'normal', 'Na': 0.19, 'K': 0.03, 'drug': 'D'}, {'age': 88, 'sex': 'M', 'BP': 'normal', 'cholesterol': 'normal', 'Na': 0.80, 'K': 0.05, 'drug': 'B'}, {'age': 39, 'sex': 'F', 'BP': 'low', 'cholesterol': 'normal', 'Na': 0.19, 'K': 0.02, 'drug': 'C'}, {'age': 43, 'sex': 'M', 'BP': 'normal', 'cholesterol': 'high', 'Na': 0.36, 'K': 0.03, 'drug': 'D'}, {'age': 82, 'sex': 'F', 'BP': 'normal', 'cholesterol': 'normal', 'Na': 0.09, 'K': 0.09, 'drug': 'C'}, {'age': 40, 'sex': 'M', 'BP': 'high', 'cholesterol': 'normal', 'Na': 0.89, 'K': 0.02, 'drug': 'A'}, {'age': 88, 'sex': 'M', 'BP': 'normal', 'cholesterol': 'normal', 'Na': 0.80, 'K': 0.05, 'drug': 'B'}, {'age': 29, 'sex': 'F', 'BP': 'high', 'cholesterol': 'normal', 'Na': 0.35, 'K': 0.04, 'drug': 'D'}, {'age': 53, 'sex': 'F', 'BP': 'normal', 'cholesterol': 'normal', 'Na': 0.54, 'K': 0.06, 'drug': 'C'}, {'age': 36, 'sex': 'F', 'BP': 'high', 'cholesterol': 'high', 'Na': 0.53, 'K': 0.05, 'drug': 'A'}, {'age': 63, 'sex': 'M', 'BP': 'low', 'cholesterol': 'high', 'Na': 0.86, 'K': 0.09, 'drug': 'B'}, {'age': 60, 'sex': 'M', 'BP': 'low', 'cholesterol': 'normal', 'Na': 0.66, 'K': 0.04, 'drug': 'C'}, {'age': 55, 'sex': 'M', 'BP': 'high', 'cholesterol': 'high', 'Na': 0.82, 'K': 0.04, 'drug': 'B'}, {'age': 35, 'sex': 'F', 'BP': 'normal', 'cholesterol': 'high', 'Na': 0.27, 'K': 0.03, 'drug': 'D'}, {'age': 23, 'sex': 'F', 'BP': 'high', 'cholesterol': 'high', 'Na': 0.55, 'K': 0.08, 'drug': 'A'}, {'age': 49, 'sex': 'F', 'BP': 'low', 'cholesterol': 'normal', 'Na': 0.27, 'K': 0.05, 'drug': 'C'}, {'age': 27, 'sex': 'M', 'BP': 'normal', 'cholesterol': 'normal', 'Na': 0.77, 'K': 0.02, 'drug': 'B'}, {'age': 51, 'sex': 'F', 'BP': 'low', 'cholesterol': 'high', 'Na': 0.20, 'K': 0.02, 'drug': 'D'}, {'age': 38, 'sex': 'M', 'BP': 'high', 'cholesterol': 'normal', 'Na': 0.78, 'K': 0.05, 'drug': 'A'}]
print(len(data))preparacion.py
import numpy as npfrom sklearn.preprocessing import OneHotEncoderfrom sklearn.model_selection import train_test_split
from data import data
age = np.array([d['age'] for d in data]).reshape(-1, 1)Na = np.array([d['Na'] for d in data]).reshape(-1, 1)K = np.array([d['K'] for d in data]).reshape(-1, 1)
cat_data = np.array([[d['sex'], d['BP'], d['cholesterol']] for d in data])
encoder = OneHotEncoder(sparse_output=False)cat_encoded = encoder.fit_transform(cat_data)cat_feature_names = encoder.get_feature_names_out(['sex', 'BP', 'cholesterol'])
X = np.column_stack([age, cat_encoded, Na, K])y = np.array([d['drug'] for d in data]).reshape(-1, 1)
feature_names = ['age'] + list(cat_feature_names) + ['Na', 'K']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=3)Código: arbol0.py (árbol con todas las características)
import numpy as npfrom sklearn import treefrom sklearn.model_selection import cross_val_score
from preparacion import X, y, X_train, X_test, y_train, y_test, feature_names
classifier = tree.DecisionTreeClassifier(random_state=1, criterion='gini')classifier.fit(X_train, y_train)
print(f"Exactitud - Test: {classifier.score(X_test, y_test):.4f}, Train: {classifier.score(X_train, y_train):.4f}")print("Árbol:\n" + tree.export_text(classifier, feature_names=feature_names))
try: arch = open("arbol0.dot", 'w') tree.export_graphviz(classifier, out_file=arch, feature_names=feature_names, class_names=np.unique(y).astype(str), filled=False, rounded=False) arch.close()except: print("No puedo abrir el archivo arbol0.dot")
print('Importancia de características:')for name, imp in zip(feature_names, classifier.feature_importances_): print(f' {name}: {imp:.4f}')
scores = cross_val_score(classifier, X, y, cv=5)print(f"Scores: {scores}, Mean: {scores.mean()}, Std: {scores.std()}")np.save("scores_arbol0.npy", scores)
prominent_features = np.argsort(classifier.feature_importances_)[-3:][::-1]names_top3 = [feature_names[i] for i in prominent_features]print(f"Top 3 características (por importancia): {names_top3}")np.save("top3_indices.npy", prominent_features)Resultados de arbol0.py:
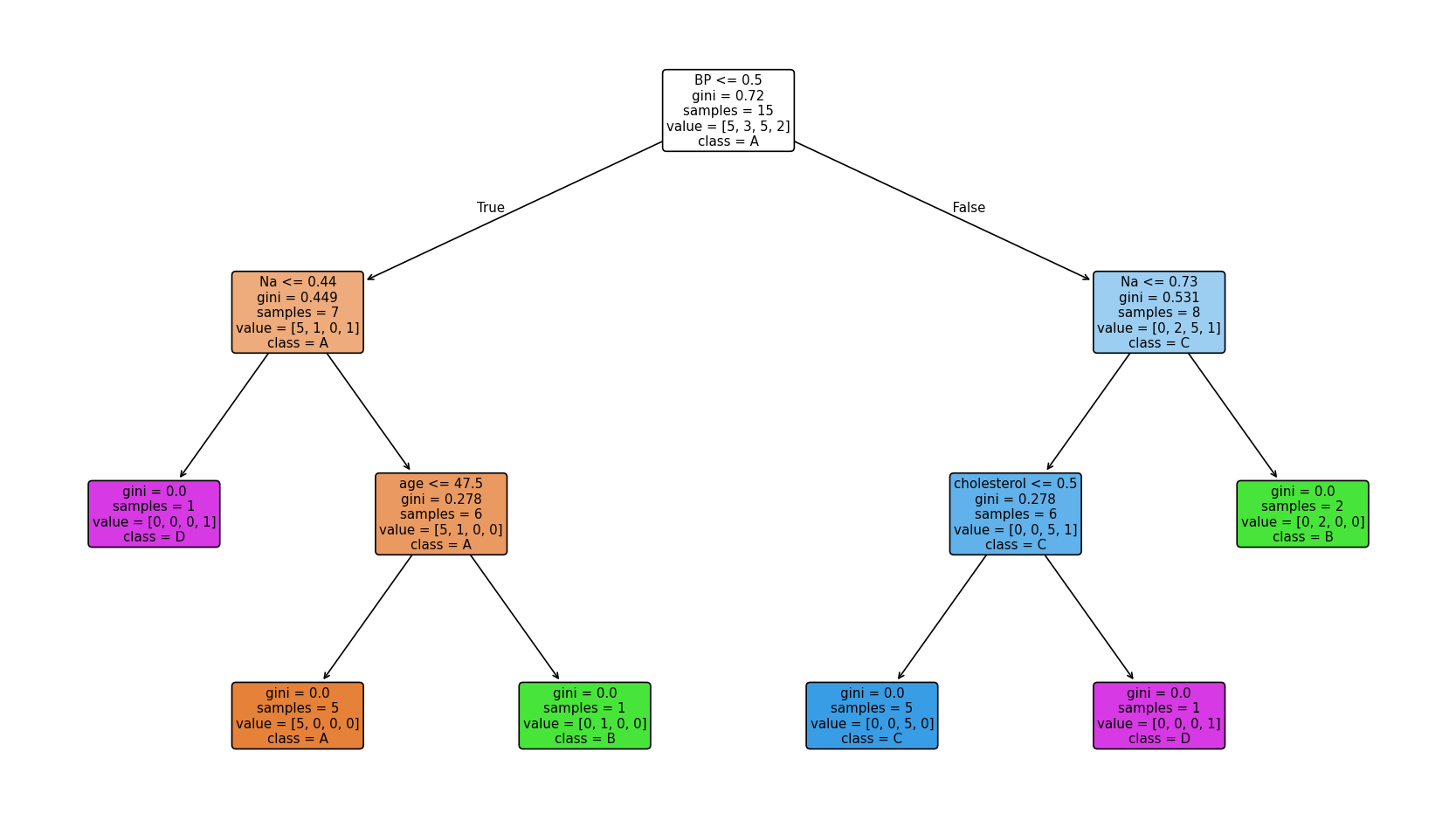
20Exactitud - Test: 1.0000, Train: 1.0000Árbol:|--- BP_high <= 0.50| |--- Na <= 0.73| | |--- cholesterol_high <= 0.50| | | |--- class: C| | |--- cholesterol_high > 0.50| | | |--- class: D| |--- Na > 0.73| | |--- class: B|--- BP_high > 0.50| |--- Na <= 0.44| | |--- class: D| |--- Na > 0.44| | |--- age <= 47.50| | | |--- class: A| | |--- age > 47.50| | | |--- class: B
Importancia de características: age: 0.1543 sex_F: 0.0000 sex_M: 0.0000 BP_high: 0.3155 BP_low: 0.0000 BP_normal: 0.0000 cholesterol_high: 0.1543 cholesterol_normal: 0.0000 Na: 0.3759 K: 0.0000Scores: [0.75 0.75 0.75 0.5 0.75], Mean: 0.7, Std: 0.09999999999999999Top 3 características (por importancia): ['Na', 'BP_high', 'cholesterol_high']Árbol con todas las características
Se entrena un árbol con las seis características (age, sex, BP, cholesterol, Na, K). Resultados:
- Exactitud: Train 1.0000, Test 1.0000 (en este split).
- Validación cruzada (5 folds): Scores [0.75, 0.75, 0.75, 0.5, 0.75], media 0.70, desv. est. 0.10.
Visualización del árbol:
Importancia de las características
| Característica | Importancia |
|---|---|
| Na | 0.3759 |
| BP_high | 0.3155 |
| cholesterol_high | 0.1543 |
| age | 0.1543 |
| sex_F | 0.0000 |
| sex_M | 0.0000 |
| BP_low | 0.0000 |
| BP_normal | 0.0000 |
| cholesterol_normal | 0.0000 |
| K | 0.0000 |
Las tres características más importantes son: Na, BP_high y cholesterol_high.
Código: arbol1.py (árbol con top 3 características)
import numpy as npfrom sklearn import treefrom sklearn.model_selection import cross_val_score
from preparacion import X, y, X_train, X_test, y_train, y_test, feature_names
prominent_features = np.load("top3_indices.npy")names_top3 = [feature_names[i] for i in prominent_features]
X_top3 = X[:, prominent_features]X_train_top = X_train[:, prominent_features]X_test_top = X_test[:, prominent_features]
classifier_top = tree.DecisionTreeClassifier(random_state=30, criterion='gini')classifier_top.fit(X_train_top, y_train)
print(f"Exactitud - Test: {classifier_top.score(X_test_top, y_test):.4f}, Train: {classifier_top.score(X_train_top, y_train):.4f}")arbol_top3_texto = tree.export_text(classifier_top, feature_names=names_top3)print("Árbol:\n" + arbol_top3_texto)try: arch = open("arbol1.txt", 'w') arch.write(arbol_top3_texto) arch.close()except: print("No puedo abrir el archivo arbol1.txt")try: arch = open("arbol1.dot", 'w') tree.export_graphviz(classifier_top, out_file=arch, feature_names=names_top3, class_names=np.unique(y).astype(str), filled=False, rounded=False) arch.close()except: print("No puedo abrir el archivo arbol1.dot")
print('Importancia de características:')for name, imp in zip(names_top3, classifier_top.feature_importances_): print(f' {name}: {imp:.4f}')
scores_top = cross_val_score(classifier_top, X_top3, y, cv=5)print(f"Scores: {scores_top}, Mean: {scores_top.mean()}, Std: {scores_top.std()}")
scores_full = np.load("scores_arbol0.npy")print(f"Comparación de exactitud media:\n Todas las características ({', '.join(feature_names)}): {scores_full.mean():.4f}\n Top 3 ({', '.join(names_top3)}): {scores_top.mean():.4f}")Resultados de arbol1.py:
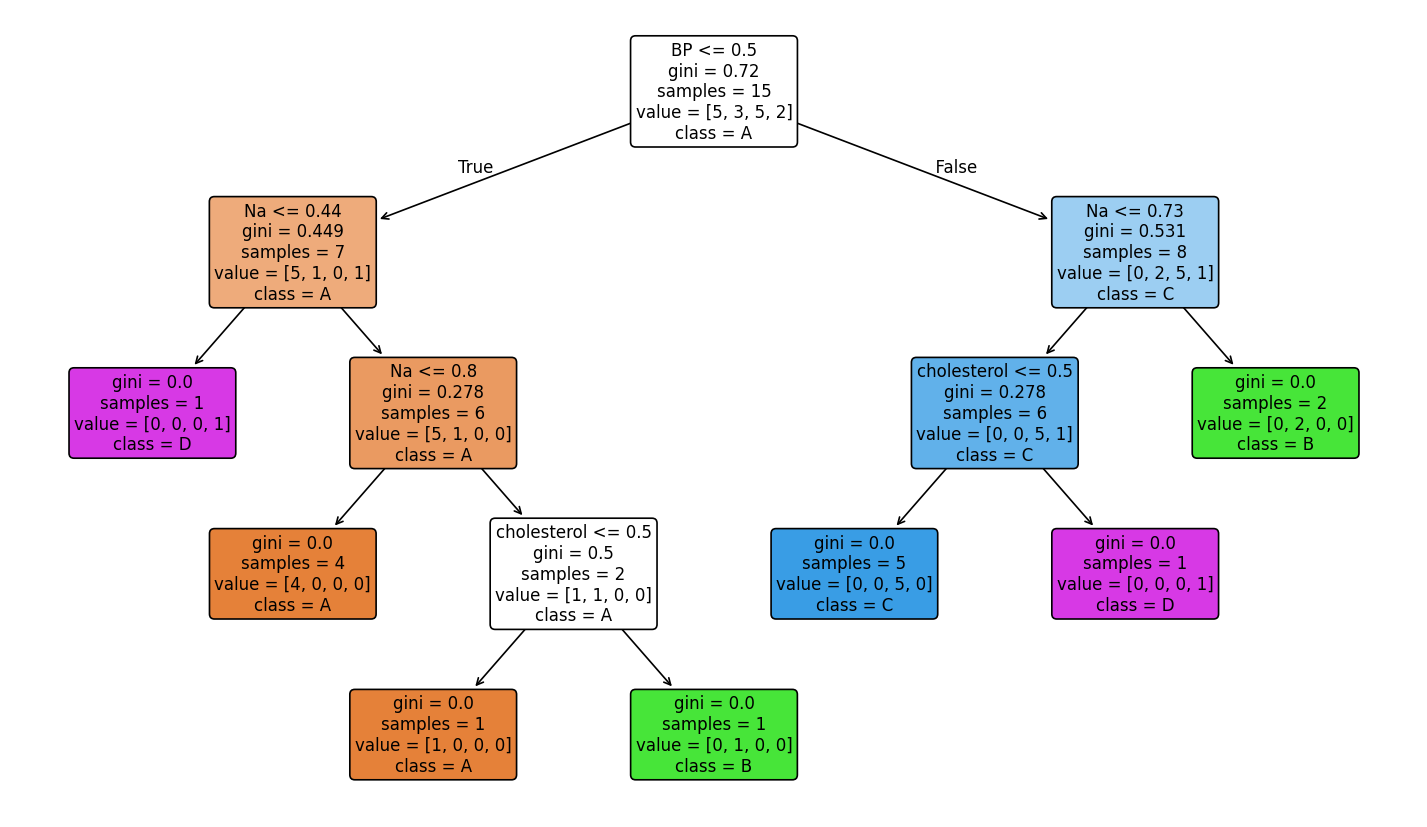
20Exactitud - Test: 1.0000, Train: 1.0000Árbol:|--- BP_high <= 0.50| |--- Na <= 0.73| | |--- cholesterol_high <= 0.50| | | |--- class: C| | |--- cholesterol_high > 0.50| | | |--- class: D| |--- Na > 0.73| | |--- class: B|--- BP_high > 0.50| |--- Na <= 0.44| | |--- class: D| |--- Na > 0.44| | |--- Na <= 0.80| | | |--- class: A| | |--- Na > 0.80| | | |--- Na <= 0.85| | | | |--- class: B| | | |--- Na > 0.85| | | | |--- class: A
Importancia de características: Na: 0.5302 BP_high: 0.3155 cholesterol_high: 0.1543Scores: [1. 0.75 1. 0.5 0.75], Mean: 0.8, Std: 0.18708286933869706Comparación de exactitud media: Todas las características (age, sex_F, sex_M, BP_high, BP_low, BP_normal, cholesterol_high, cholesterol_normal, Na, K): 0.7000 Top 3 (Na, BP_high, cholesterol_high): 0.8000Árbol con las tres características más importantes
Se reentrena un árbol usando solo Na, BP_high y cholesterol_high. Resultados:
- Exactitud: Train 1.0000, Test 1.0000 (en este split).
- Validación cruzada (5 folds): Scores [1.0, 0.75, 1.0, 0.5, 0.75], media 0.80, desv. est. ≈ 0.187.
Visualización del árbol (top 3):
Comparación: todas las características vs top 3
| Modelo | Exactitud media (validación cruzada) |
|---|---|
| Todas (10 características, codificadas) | 0.7000 |
| Top 3 (Na, BP_high, cholesterol_high) | 0.8000 |
En esta experiencia, el árbol con solo las tres características más importantes (sobre todo identificando explícitamente valores altos en presión y colesterol) obtiene mejor exactitud media en validación cruzada (0.80) que el árbol con las diez características (0.70), lo que sugiere que el modelo completo puede estar sobreajustando a variables menos ruidosas como la edad en vez de enfocarse en las principales; el modelo reducido generaliza mejor con estos datos.
Respuestas
¿Cuál fue el razonamiento del médico para recetar cada medicina?
El árbol de decisión refleja un criterio en cascada que aprovecha ahora codificaciones directas (high vs no high): el médico separa primero por presión arterial alta (BP_high) y luego usa sodio (Na) y, en algunos casos, colesterol alto e indirectamente la edad. Así se resume el razonamiento:
- Medicamento D: Se receta a dos perfiles principales: (1) BP normal/baja (BP_high <= 0.5) donde el colesterol es alto y el Na es moderado o bajo (<= 0.73), y (2) en perfiles de paciente con BP alta pero con niveles bajos de Na (<= 0.44).
- Medicamento C: Corresponde a pacientes con BP normal o baja (BP_high <= 0.5), sodio bajo o moderado (Na <= 0.73) y colesterol que no es explícitamente alto.
- Medicamento B: Aparece en pacientes que tienen un elevado nivel de sodio en la sangre (Na > 0.73) cuando la presión es normal/baja, y en individuos con BP alta y Na elevado si tienen más de 47.5 años de edad.
- Medicamento A: Exclusivamente asociado con presión alta (BP_high > 0.5), en pacientes más jóvenes (edad <= 47.5) que tienen niveles de sodio no críticamente bajos (Na > 0.44).
En conjunto, el médico parece seguir reglas basadas en umbrales de alta presión, alto colesterol y cortes definidos de sodio, mostrando patrones de prescripción dependientes de condiciones particulares.
¿Se puede ver la relación entre los valores en sangre y la medicina que el médico recetó?
Sí, y es sumamente clara para el sodio (Na). Na es la variable general con mayor peso predictivo en la decisión e integra los principales divisores lógicos del razonamiento (0.37 a 0.53 de importancia). Picos bajos dirigen explícitamente a fármacos D y C, valores moderados hacia A, y picos concentrados altos inducen la prescripción de B. La nueva codificación expone con especial fuerza el rol contundente de las variables categóricas específicas BP_high (0.31) y cholesterol_high (0.15). A la par, el potasio (K) se mantiene consistente en no aportar peso predictivo a los árboles probados (importancia 0 en ambos esquemas); en esta muestra reducida su valor no sirve de discriminante para elegir tratamientos.
Conclusiones
Los árboles de decisión permiten explicar la relación entre variables clínicas y valores en sangre. Tras implementar una codificación One-Hot para aislar variables como “Presión Alta” y “Colesterol Alto”, el modelo se enfoca en que Na, BP_high y cholesterol_high son las más útiles. Curiosamente, la exactitud media sube a 0.80 en validación cruzada con solo esas 3 subvariables frente al 0.70 con todo el conjunto. Esto afirma la importancia de proveerle a los árboles de toma de decisiones características pre-procesadas de una manera lógica; un codificador nominal (“high” no es número inherentemente relativo a “normal” numéricamente hablando para el árbol) fue preferible para modelar mejor frente al anterior acercamiento.