
Información de la Tarea
Estudiante: Andrés Cruz Chipol
Curso: Aprendizaje Automático
Fecha de entrega: Jueves 26 de febrero, 2026
Descripción de la Tarea
Se trabaja con un conjunto de datos donde, a partir de variables clínicas y valores en sangre (edad, sexo, presión arterial, colesterol, sodio Na y potasio K), un médico asigna uno de cuatro medicamentos (A, B, C o D). Con estos datos se debe contestar las preguntas siguientes y cumplir los requisitos de entrega.
Preguntas a contestar
- ¿Cuál fue el razonamiento del médico para recetar cada medicina?
- ¿Se puede ver la relación entre los valores en sangre y la medicina que el médico recetó?
Requisitos de entrega
- Usar validación cruzada.
- Visualizar el mejor árbol.
- Reportar la importancia de las características.
- Usar las tres características más importantes, reentrenar el clasificador y comparar su rendimiento con el obtenido usando todas las características.
Datos y preprocesamiento
El dataset contiene 20 registros con las variables: age, sex, BP (presión arterial: low, normal, high), cholesterol (normal, high), Na (sodio), K (potasio) y la clase drug (A, B, C o D). Código de datos y preprocesamiento:
data.py
data = [ {'age': 33, 'sex': 'F', 'BP': 'high', 'cholesterol': 'high', 'Na': 0.66, 'K': 0.06, 'drug': 'A'}, {'age': 77, 'sex': 'F', 'BP': 'high', 'cholesterol': 'normal', 'Na': 0.19, 'K': 0.03, 'drug': 'D'}, {'age': 88, 'sex': 'M', 'BP': 'normal', 'cholesterol': 'normal', 'Na': 0.80, 'K': 0.05, 'drug': 'B'}, {'age': 39, 'sex': 'F', 'BP': 'low', 'cholesterol': 'normal', 'Na': 0.19, 'K': 0.02, 'drug': 'C'}, {'age': 43, 'sex': 'M', 'BP': 'normal', 'cholesterol': 'high', 'Na': 0.36, 'K': 0.03, 'drug': 'D'}, {'age': 82, 'sex': 'F', 'BP': 'normal', 'cholesterol': 'normal', 'Na': 0.09, 'K': 0.09, 'drug': 'C'}, {'age': 40, 'sex': 'M', 'BP': 'high', 'cholesterol': 'normal', 'Na': 0.89, 'K': 0.02, 'drug': 'A'}, {'age': 88, 'sex': 'M', 'BP': 'normal', 'cholesterol': 'normal', 'Na': 0.80, 'K': 0.05, 'drug': 'B'}, {'age': 29, 'sex': 'F', 'BP': 'high', 'cholesterol': 'normal', 'Na': 0.35, 'K': 0.04, 'drug': 'D'}, {'age': 53, 'sex': 'F', 'BP': 'normal', 'cholesterol': 'normal', 'Na': 0.54, 'K': 0.06, 'drug': 'C'}, {'age': 36, 'sex': 'F', 'BP': 'high', 'cholesterol': 'high', 'Na': 0.53, 'K': 0.05, 'drug': 'A'}, {'age': 63, 'sex': 'M', 'BP': 'low', 'cholesterol': 'high', 'Na': 0.86, 'K': 0.09, 'drug': 'B'}, {'age': 60, 'sex': 'M', 'BP': 'low', 'cholesterol': 'normal', 'Na': 0.66, 'K': 0.04, 'drug': 'C'}, {'age': 55, 'sex': 'M', 'BP': 'high', 'cholesterol': 'high', 'Na': 0.82, 'K': 0.04, 'drug': 'B'}, {'age': 35, 'sex': 'F', 'BP': 'normal', 'cholesterol': 'high', 'Na': 0.27, 'K': 0.03, 'drug': 'D'}, {'age': 23, 'sex': 'F', 'BP': 'high', 'cholesterol': 'high', 'Na': 0.55, 'K': 0.08, 'drug': 'A'}, {'age': 49, 'sex': 'F', 'BP': 'low', 'cholesterol': 'normal', 'Na': 0.27, 'K': 0.05, 'drug': 'C'}, {'age': 27, 'sex': 'M', 'BP': 'normal', 'cholesterol': 'normal', 'Na': 0.77, 'K': 0.02, 'drug': 'B'}, {'age': 51, 'sex': 'F', 'BP': 'low', 'cholesterol': 'high', 'Na': 0.20, 'K': 0.02, 'drug': 'D'}, {'age': 38, 'sex': 'M', 'BP': 'high', 'cholesterol': 'normal', 'Na': 0.78, 'K': 0.05, 'drug': 'A'}]
print(len(data))preparacion.py
import numpy as npfrom sklearn.preprocessing import LabelEncoderfrom sklearn.model_selection import train_test_split
from data import data
feature_names = ['age', 'sex', 'BP', 'cholesterol', 'Na', 'K']
age = np.array([d['age'] for d in data]).reshape(-1, 1)sex = np.array([0 if d['sex'] == 'F' else 1 for d in data]).reshape(-1, 1)lbencoder = LabelEncoder()lbencoder.fit(['low', 'normal', 'high'])bp = np.array(lbencoder.fit_transform([d['BP'] for d in data])).reshape(-1, 1)cholesterol = np.array([0 if d['cholesterol'] == 'normal' else 1 for d in data]).reshape(-1, 1)Na = np.array([d['Na'] for d in data]).reshape(-1, 1)K = np.array([d['K'] for d in data]).reshape(-1, 1)
X = np.column_stack([age, sex, bp, cholesterol, Na, K])y = np.array([d['drug'] for d in data]).reshape(-1, 1)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=3)Código: arbol0.py (árbol con todas las características)
import numpy as npfrom sklearn import treefrom sklearn.model_selection import cross_val_score
from preparacion import X, y, X_train, X_test, y_train, y_test, feature_names
classifier = tree.DecisionTreeClassifier(random_state=1, criterion='gini')classifier.fit(X_train, y_train)
print(f"Exactitud - Test: {classifier.score(X_test, y_test):.4f}, Train: {classifier.score(X_train, y_train):.4f}")print("Árbol:\n" + tree.export_text(classifier, feature_names=feature_names))
try: arch = open("arbol0.dot", 'w') tree.export_graphviz(classifier, out_file=arch, feature_names=feature_names, class_names=np.unique(y).astype(str), filled=False, rounded=False) arch.close()except: print("No puedo abrir el archivo arbol0.dot")
print('Importancia de características:')for name, imp in zip(feature_names, classifier.feature_importances_): print(f' {name}: {imp:.4f}')
scores = cross_val_score(classifier, X, y, cv=5)print(f"Scores: {scores}, Mean: {scores.mean()}, Std: {scores.std()}")np.save("scores_arbol0.npy", scores)
prominent_features = np.argsort(classifier.feature_importances_)[-3:][::-1]names_top3 = [feature_names[i] for i in prominent_features]print(f"Top 3 características (por importancia): {names_top3}")np.save("top3_indices.npy", prominent_features)Resultados de arbol0.py:
20Exactitud - Test: 1.0000, Train: 1.0000Árbol:|--- BP <= 0.50| |--- Na <= 0.44| | |--- class: D| |--- Na > 0.44| | |--- age <= 47.50| | | |--- class: A| | |--- age > 47.50| | | |--- class: B|--- BP > 0.50| |--- Na <= 0.73| | |--- cholesterol <= 0.50| | | |--- class: C| | |--- cholesterol > 0.50| | | |--- class: D| |--- Na > 0.73| | |--- class: B
Importancia de características: age: 0.1543 sex: 0.0000 BP: 0.3155 cholesterol: 0.1543 Na: 0.3759 K: 0.0000Scores: [0.75 0.75 0.75 0.5 0.25], Mean: 0.6, Std: 0.2Top 3 características (por importancia): ['Na', 'BP', 'cholesterol']Árbol con todas las características
Se entrena un árbol con las seis características (age, sex, BP, cholesterol, Na, K). Resultados:
- Exactitud: Train 1.0000, Test 1.0000 (en este split).
- Validación cruzada (5 folds): Scores [0.75, 0.75, 0.75, 0.5, 0.25], media 0.60, desv. est. 0.20.
Visualización del árbol:
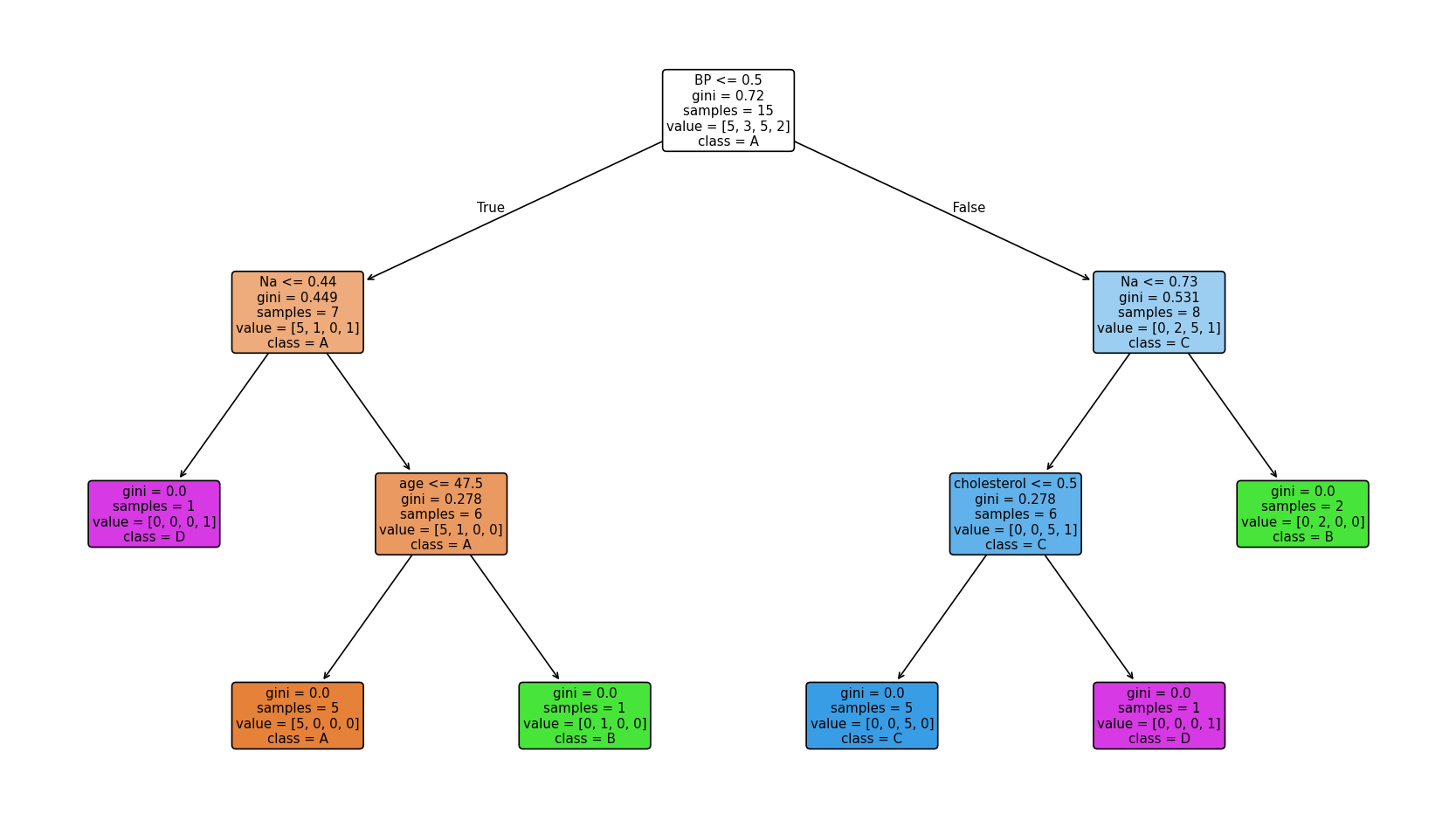
Importancia de las características
| Característica | Importancia |
|---|---|
| Na | 0.3759 |
| BP | 0.3155 |
| cholesterol | 0.1543 |
| age | 0.1543 |
| sex | 0.0000 |
| K | 0.0000 |
Las tres características más importantes son: Na, BP y cholesterol.
Código: arbol1.py (árbol con top 3 características)
import numpy as npfrom sklearn import treefrom sklearn.model_selection import cross_val_score
from preparacion import X, y, X_train, X_test, y_train, y_test, feature_names
prominent_features = np.load("top3_indices.npy")names_top3 = [feature_names[i] for i in prominent_features]
X_top3 = X[:, prominent_features]X_train_top = X_train[:, prominent_features]X_test_top = X_test[:, prominent_features]
classifier_top = tree.DecisionTreeClassifier(random_state=30, criterion='gini')classifier_top.fit(X_train_top, y_train)
print(f"Exactitud - Test: {classifier_top.score(X_test_top, y_test):.4f}, Train: {classifier_top.score(X_train_top, y_train):.4f}")arbol_top3_texto = tree.export_text(classifier_top, feature_names=names_top3)print("Árbol:\n" + arbol_top3_texto)try: arch = open("arbol1.txt", 'w') arch.write(arbol_top3_texto) arch.close()except: print("No puedo abrir el archivo arbol1.txt")try: arch = open("arbol1.dot", 'w') tree.export_graphviz(classifier_top, out_file=arch, feature_names=names_top3, class_names=np.unique(y).astype(str), filled=False, rounded=False) arch.close()except: print("No puedo abrir el archivo arbol1.dot")
print('Importancia de características:')for name, imp in zip(names_top3, classifier_top.feature_importances_): print(f' {name}: {imp:.4f}')
scores_top = cross_val_score(classifier_top, X_top3, y, cv=5)print(f"Scores: {scores_top}, Mean: {scores_top.mean()}, Std: {scores_top.std()}")
scores_full = np.load("scores_arbol0.npy")print(f"Comparación de exactitud media:\n Todas las características ({', '.join(feature_names)}): {scores_full.mean():.4f}\n Top 3 ({', '.join(names_top3)}): {scores_top.mean():.4f}")Resultados de arbol1.py:
20Exactitud - Test: 1.0000, Train: 1.0000Árbol:|--- BP <= 0.50| |--- Na <= 0.44| | |--- class: D| |--- Na > 0.44| | |--- Na <= 0.80| | | |--- class: A| | |--- Na > 0.80| | | |--- cholesterol <= 0.50| | | | |--- class: A| | | |--- cholesterol > 0.50| | | | |--- class: B|--- BP > 0.50| |--- Na <= 0.73| | |--- cholesterol <= 0.50| | | |--- class: C| | |--- cholesterol > 0.50| | | |--- class: D| |--- Na > 0.73| | |--- class: B
Importancia de características: Na: 0.4376 BP: 0.3155 cholesterol: 0.2469Scores: [1. 1. 0.5 0.5 0.75], Mean: 0.75, Std: 0.22360679774997896Comparación de exactitud media: Todas las características (age, sex, BP, cholesterol, Na, K): 0.6000 Top 3 (Na, BP, cholesterol): 0.7500Árbol con las tres características más importantes
Se reentrena un árbol usando solo Na, BP y cholesterol. Resultados:
- Exactitud: Train 1.0000, Test 1.0000 (en este split).
- Validación cruzada (5 folds): Scores [1.0, 1.0, 0.5, 0.5, 0.75], media 0.75, desv. est. ≈ 0.22.
Visualización del árbol (top 3):
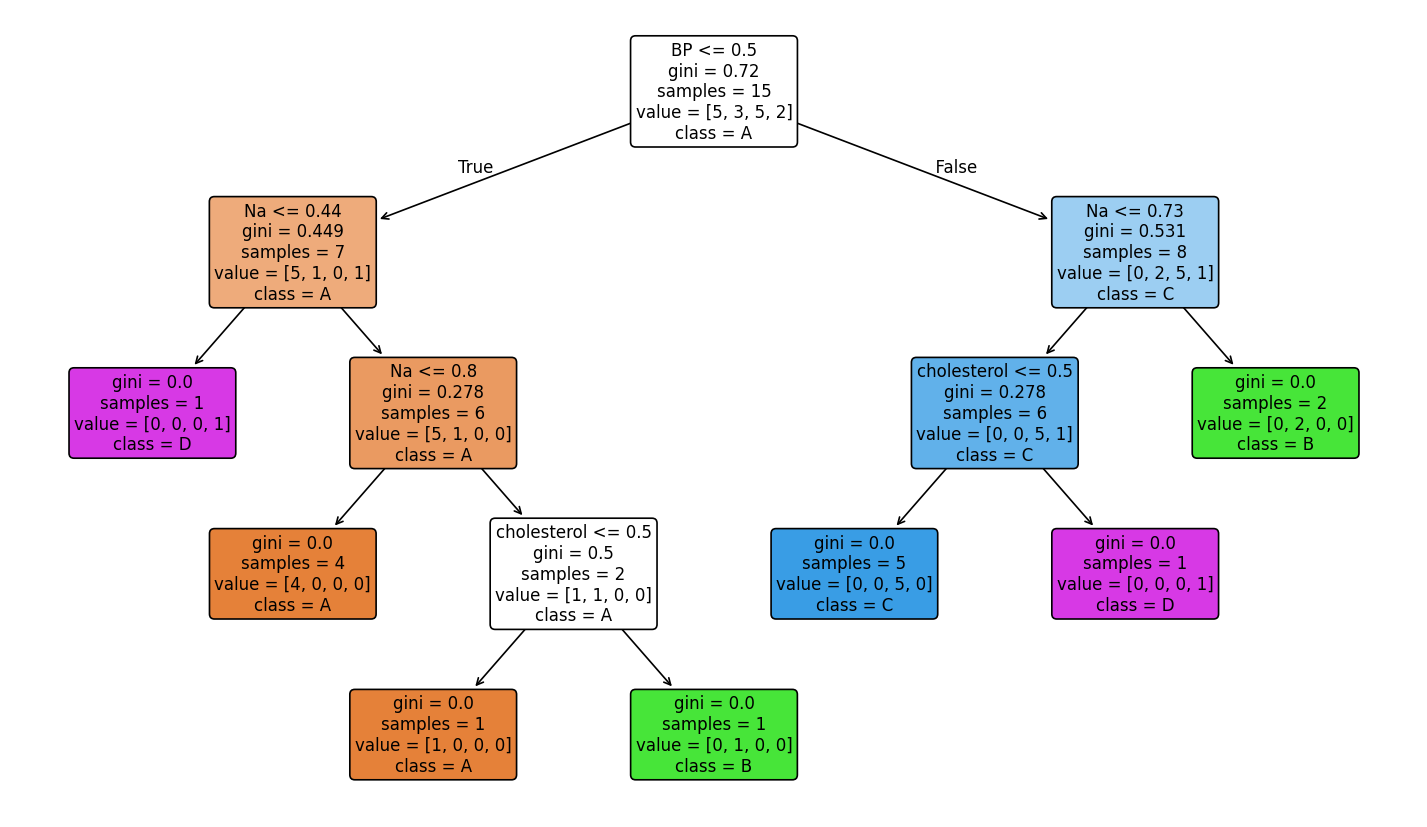
Comparación: todas las características vs top 3
| Modelo | Exactitud media (validación cruzada) |
|---|---|
| Todas (6 características) | 0.6000 |
| Top 3 (Na, BP, cholesterol) | 0.7500 |
En esta experiencia, el árbol con solo las tres características más importantes obtiene mejor exactitud media en validación cruzada (0.75) que el árbol con las seis características (0.60), lo que sugiere que el modelo completo puede estar sobreajustando en algunos folds; el modelo reducido generaliza mejor con estos datos.
Respuestas
¿Cuál fue el razonamiento del médico para recetar cada medicina?
El árbol de decisión refleja un criterio en cascada: el médico separa primero por presión arterial (BP) y luego usa sodio (Na) y, en algunos casos, colesterol y edad. Así se puede resumir el razonamiento por medicamento:
- Medicamento D: Se asocia a dos perfiles: (1) BP baja y Na bajo (≤ 0.44), o (2) BP normal/alta, Na no alto (≤ 0.73) y colesterol alto. Es decir, D se elige cuando el sodio está bajo o cuando hay colesterol alto con sodio moderado, según el nivel de presión.
- Medicamento A: BP baja, Na por encima de 0.44 y edad ≤ 47.5 años. Corresponde a pacientes más jóvenes con BP baja y sodio no bajo.
- Medicamento B: Aparece en dos ramas: (1) BP baja, Na > 0.44 y edad > 47.5, o (2) BP normal/alta y Na alto (> 0.73). En la práctica, B se asocia a sodio alto o a ese perfil de edad cuando el sodio no es bajo.
- Medicamento C: BP normal o alta, Na ≤ 0.73 y colesterol normal. Es el único que requiere explícitamente colesterol normal con sodio bajo o moderado y presión no baja.
En conjunto, el médico parece seguir reglas basadas en umbrales de BP, Na y colesterol (y edad en una rama), lo que sugiere que la elección del fármaco depende de combinaciones concretas de estos factores más que de una sola variable.
¿Se puede ver la relación entre los valores en sangre y la medicina que el médico recetó?
Sí, y es especialmente clara para el sodio (Na). Na es la variable con mayor importancia en el árbol (0.376) y aparece en todas las ramas con umbrales bien definidos (0.44, 0.73 y 0.80 en el árbol con top 3). Esos cortes separan a los pacientes en grupos que reciben D, A, B o C: valores bajos de Na suelen llevar a D o C según BP y colesterol; valores altos de Na llevan sobre todo a B (y en una rama a A cuando además la edad es menor). Es decir, hay una relación clara entre el nivel de Na en sangre y el medicamento recetado. En cambio, potasio (K) tiene importancia 0 en el modelo: en estos datos no aporta para predecir la medicina, ya sea porque el médico no lo usaba como criterio principal o porque en esta muestra no discrimina entre fármacos. La relación “valores en sangre ↔ medicina” es por tanto fuerte para Na y no apreciable para K en este árbol.
Conclusiones
Los árboles de decisión permiten explicar la relación entre variables clínicas y valores en sangre y el medicamento recetado mediante reglas interpretables. La importancia de características indica que Na, BP y cholesterol son las más útiles para esta clasificación; con solo esas tres se logra en validación cruzada una exactitud media mayor que con las seis, mostrando el valor de la selección de características. La validación cruzada es necesaria para evaluar el rendimiento real, ya que las exactitudes en un solo train/test pueden ser engañosas (en este caso 1.0 en ambos modelos). Para obtener el mejor modelo se probaron distintos valores de random_state tanto en el split train/test como en los clasificadores (árbol con todas las características y árbol con top 3), hasta elegir las semillas con las que se reportan los resultados anteriores.