
Información de la Tarea
Estudiante: Andrés Cruz Chipol
Curso: Aprendizaje Automático
Fecha de entrega: 12 de Febrero, 2026
Descripción de la Tarea
Este modelo es la MVS (Máquina de Vectores de Soporte / SVM). Compare el modelo MVS con la regresión logística y los K vecinos más cercanos. Use 5 y 10 dobleces para calcular las estadísticas de los tres modelos de clasificación.
Evaluación de los algoritmos
Introducción
Se trabajó con el conjunto de datos blobs_1.csv, con características escaladas en el intervalo [-1, 1] y etiquetas binarias. Los tres modelos evaluados son: SVM (MVS) con kernel lineal, regresión logística y K vecinos más cercanos (K=5). Para reproducibilidad se usó random_state=1 en todos los modelos. La evaluación se realizó mediante validación cruzada con 5 y 10 dobleces, calculando para cada configuración la media y la desviación estándar de la exactitud.
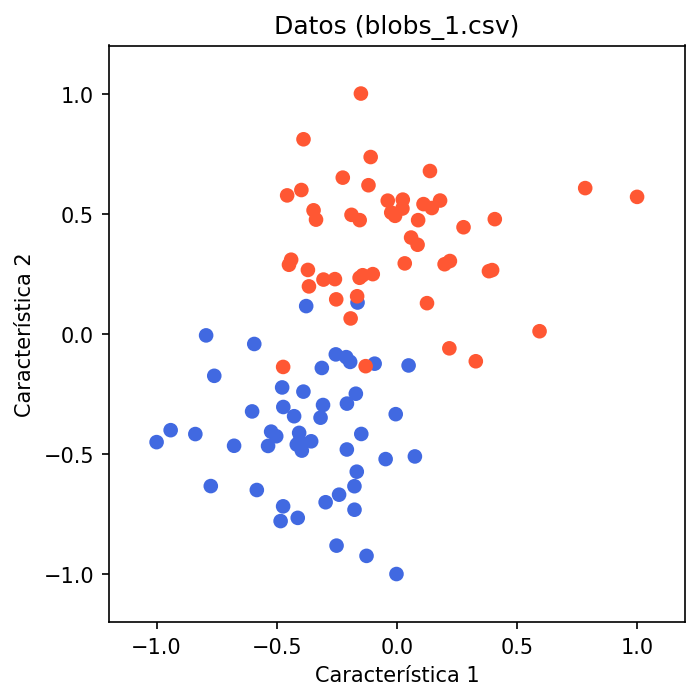
Datos — blobs_1.csv
Formato: característica1, característica2, etiqueta (0 o 1).
7.51252e-02,-5.10505e-01,0.00000e+00-1.00000e+00,-4.50967e-01,0.00000e+00-1.63553e-01,1.30125e-01,0.00000e+00-2.57690e-01,2.27527e-01,1.00000e+002.32321e-02,5.21439e-01,1.00000e+00-2.10706e-01,-9.72192e-02,0.00000e+00-1.76206e-01,-7.32251e-01,0.00000e+00-4.56508e-01,5.76068e-01,1.00000e+00-4.77381e-01,-2.23298e-01,0.00000e+004.89597e-02,-1.31775e-01,0.00000e+008.86209e-02,4.72994e-01,1.00000e+002.77595e-01,4.43528e-01,1.00000e+00-3.88877e-01,-2.40714e-01,0.00000e+00-2.33257e-02,5.04604e-01,1.00000e+00-5.93432e-01,-4.24042e-02,0.00000e+00-4.48927e-01,2.87350e-01,1.00000e+00-2.07731e-01,-2.90625e-01,0.00000e+00-3.46663e-01,5.13990e-01,1.00000e+00-7.59950e-01,-1.74939e-01,0.00000e+00-1.70628e-01,-2.49425e-01,0.00000e+00-2.54011e-01,-8.57463e-02,0.00000e+00-1.18062e-01,6.18375e-01,1.00000e+00-7.42734e-03,4.91016e-01,1.00000e+00-1.66782e-01,-5.74006e-01,0.00000e+00-2.50909e-01,-8.81768e-01,0.00000e+00-5.35957e-01,-4.66809e-01,0.00000e+00-1.65270e-01,1.56205e-01,1.00000e+00-9.41470e-01,-4.01192e-01,0.00000e+00-9.23711e-02,-1.24382e-01,0.00000e+00-1.29782e-01,-1.34780e-01,1.00000e+00-1.88650e-01,4.95147e-01,1.00000e+00-3.97364e-01,5.98460e-01,1.00000e+001.37865e-01,6.77555e-01,1.00000e+00-2.96387e-01,-7.01202e-01,0.00000e+00-4.83744e-01,-7.79581e-01,0.00000e+00-6.77438e-01,-4.66092e-01,0.00000e+00-7.93849e-01,-6.64203e-03,0.00000e+00-3.88508e-01,8.09651e-01,1.00000e+00-2.40371e-01,-6.69719e-01,0.00000e+002.47743e-02,5.58460e-01,1.00000e+001.45753e-01,5.23487e-01,1.00000e+00-5.82807e-01,-6.50272e-01,0.00000e+00-1.94281e-01,-1.17028e-01,0.00000e+005.93916e-02,4.00592e-01,1.00000e+00-4.73235e-01,-1.37959e-01,1.00000e+00-3.56565e-01,-4.47497e-01,0.00000e+00-3.36403e-01,4.75163e-01,1.00000e+001.11038e-01,5.39770e-01,1.00000e+00-4.73318e-01,-7.18191e-01,0.00000e+00-3.65815e-01,1.97297e-01,1.00000e+00-4.05071e-01,-4.46827e-01,0.00000e+00-1.08916e-01,7.35775e-01,1.00000e+001.98783e-01,2.89548e-01,1.00000e+00-1.42268e-01,2.43746e-01,1.00000e+00-5.02030e-01,-4.26473e-01,0.00000e+001.25566e-01,1.27492e-01,1.00000e+00-4.62922e-03,-3.34554e-01,0.00000e+00-1.54616e-01,4.73074e-01,1.00000e+00-1.76473e-01,-6.34477e-01,0.00000e+00-3.05360e-01,2.25685e-01,1.00000e+00-1.54999e-01,2.33178e-01,1.00000e+003.28704e-01,-1.14360e-01,1.00000e+00-4.27561e-01,-3.43133e-01,0.00000e+00-1.49538e-01,1.00000e+00,1.00000e+002.18611e-01,-6.05014e-02,1.00000e+00-2.08094e-01,-4.81606e-01,0.00000e+00-4.16441e-01,-4.60932e-01,0.00000e+00-1.00130e-01,2.48307e-01,1.00000e+003.29715e-02,2.93055e-01,1.00000e+00-4.66106e-02,-5.21576e-01,0.00000e+003.96651e-01,2.65167e-01,1.00000e+004.07785e-01,4.77185e-01,1.00000e+001.79963e-01,5.54630e-01,1.00000e+002.20889e-01,3.02898e-01,1.00000e+00-4.72543e-01,-3.04735e-01,0.00000e+003.83423e-01,2.60660e-01,1.00000e+00-7.74402e-01,-6.33875e-01,0.00000e+00-5.23199e-01,-4.07291e-01,0.00000e+00-4.06594e-01,-4.12464e-01,0.00000e+00-2.52307e-01,1.43306e-01,1.00000e+00-1.50059e-03,-1.00000e+00,0.00000e+00-3.17516e-01,-3.49199e-01,0.00000e+005.94072e-01,1.06205e-02,1.00000e+007.84058e-01,6.06431e-01,1.00000e+00-1.26128e-01,-9.24394e-01,0.00000e+00-3.70161e-01,2.65775e-01,1.00000e+00-3.78060e-02,5.54174e-01,1.00000e+00-1.47952e-01,-4.16979e-01,0.00000e+00-2.24997e-01,6.49980e-01,1.00000e+00-3.12191e-01,-1.42229e-01,0.00000e+001.00000e+00,5.69927e-01,1.00000e+00-8.38716e-01,-4.17397e-01,0.00000e+00-3.77298e-01,1.15293e-01,0.00000e+00-4.39926e-01,3.08375e-01,1.00000e+00-6.02392e-01,-3.23093e-01,0.00000e+00-3.95472e-01,-4.86250e-01,0.00000e+00-1.92328e-01,6.38753e-02,1.00000e+00-4.12423e-01,-7.66193e-01,0.00000e+00-3.07205e-01,-2.96457e-01,0.00000e+008.63732e-02,3.70645e-01,1.00000e+00Código de evaluación
El siguiente script carga los datos, define los tres clasificadores y ejecuta cross_val_score para 5 y 10 dobleces, imprimiendo una tabla con Modelo, Dobleces, Media, Std y los scores de cada fold:
import numpy as npfrom sklearn.model_selection import cross_val_scorefrom sklearn.svm import SVCfrom sklearn.linear_model import LogisticRegressionfrom sklearn.neighbors import KNeighborsClassifier
# DatosD = np.loadtxt("blobs_1.csv", delimiter=',')X = D[:, 0:2]y = D[:, 2]
modelos = [ ("SVM (MVS)", SVC(kernel='linear', C=1, random_state=1)), ("Regresión logística", LogisticRegression(random_state=1)), ("K vecinos (K=5)", KNeighborsClassifier(n_neighbors=5)),]
# Evaluación: validación cruzada para cada modelo y cada número de doblecesresultados = []for nombre, modelo in modelos: for k in [5, 10]: scores = cross_val_score(modelo, X, y, cv=k) media = np.mean(scores) std = np.std(scores) scores_texto = " ".join(f"{s:.4f}" for s in scores) resultados.append((nombre, k, scores_texto, media, std))
# Tablaprint(f"{'Modelo':<24} {'Dobles':<8} {'Media':<8} {'Std':<8} Scores")print("-" * 50 + " " + "-" * 50)for nombre, k, scores_texto, media, std in resultados: print(f"{nombre:<24} {k:<8} {media:.4f} {std:.4f} {scores_texto}")Resultados
Tabla de estadísticas (Media y Std de exactitud) para los tres modelos con 5 y 10 dobleces:
| Modelo | Dobles | Media | Std | Scores ||--------|--------|-------|-----|--------|| SVM (MVS) | 5 | 0.9500 | 0.0447 | 0.9000 0.9000 1.0000 1.0000 0.9500 || SVM (MVS) | 10 | 0.9500 | 0.0500 | 0.9000 0.9000 0.9000 0.9000 1.0000 1.0000 1.0000 1.0000 1.0000 0.9000 || Regresión logística | 5 | 0.9500 | 0.0447 | 0.9000 0.9000 1.0000 1.0000 0.9500 || Regresión logística | 10 | 0.9500 | 0.0500 | 0.9000 0.9000 0.9000 0.9000 1.0000 1.0000 1.0000 1.0000 1.0000 0.9000 || K vecinos (K=5) | 5 | 0.9300 | 0.0400 | 0.9500 0.9000 1.0000 0.9000 0.9000 || K vecinos (K=5) | 10 | 0.9400 | 0.0663 | 0.9000 1.0000 0.9000 0.9000 1.0000 1.0000 0.9000 1.0000 1.0000 0.8000 |Código de las gráficas
El script graficas_modelos.py genera las cuatro imágenes: primero la gráfica de los datos y luego la superficie de decisión de cada modelo (SVM, regresión logística, K-NN) usando contourf sobre una malla y scatter de los puntos.
import numpy as npimport matplotlib.pyplot as pltfrom matplotlib.colors import ListedColormapfrom sklearn.svm import SVCfrom sklearn.linear_model import LogisticRegressionfrom sklearn.neighbors import KNeighborsClassifier
# DatosD = np.loadtxt("blobs_1.csv", delimiter=',')X = D[:, 0:2]y = D[:, 2]
# Rango de ejes y malla para las superficies de decisiónx_min, x_max = X[:, 0].min() - 0.2, X[:, 0].max() + 0.2y_min, y_max = X[:, 1].min() - 0.2, X[:, 1].max() + 0.2ejes_x = np.arange(x_min, x_max, 0.02)ejes_y = np.arange(y_min, y_max, 0.02)xx, yy = np.meshgrid(ejes_x, ejes_y)grilla = np.c_[xx.ravel(), yy.ravel()]
def mismo_ejes(ax): ax.set_xlim(x_min, x_max) ax.set_ylim(y_min, y_max) ax.set_aspect('equal') ax.set_xlabel('Característica 1') ax.set_ylabel('Característica 2')
# Gráfica de los datoscmap_clases = ListedColormap(['royalblue', '#FF5733'])fig, ax = plt.subplots()ax.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_clases)mismo_ejes(ax)ax.set_title('Datos (blobs_1.csv)')plt.tight_layout()plt.savefig('01_datos.png', dpi=150, bbox_inches='tight')plt.close()
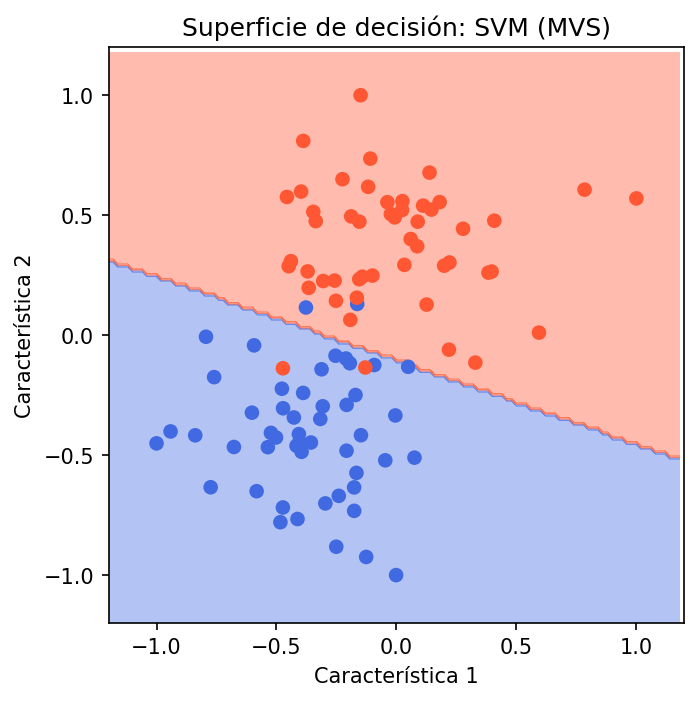
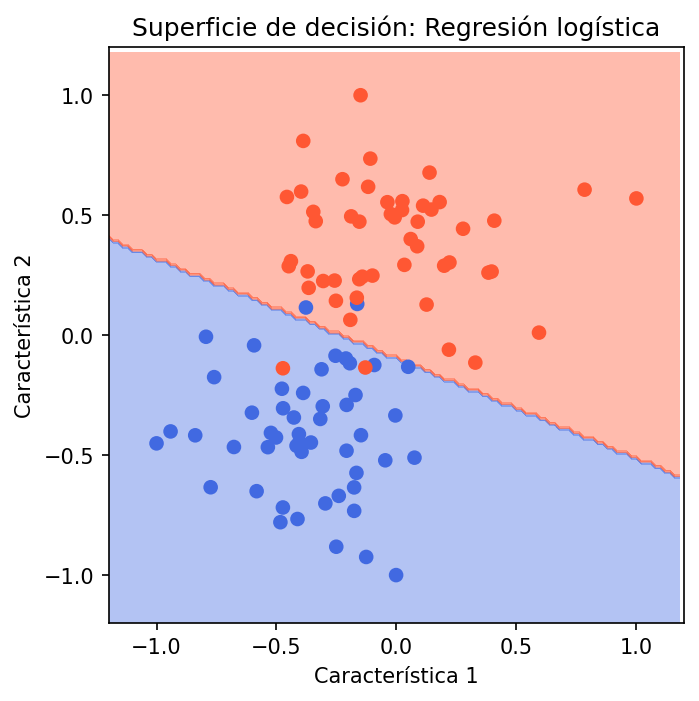
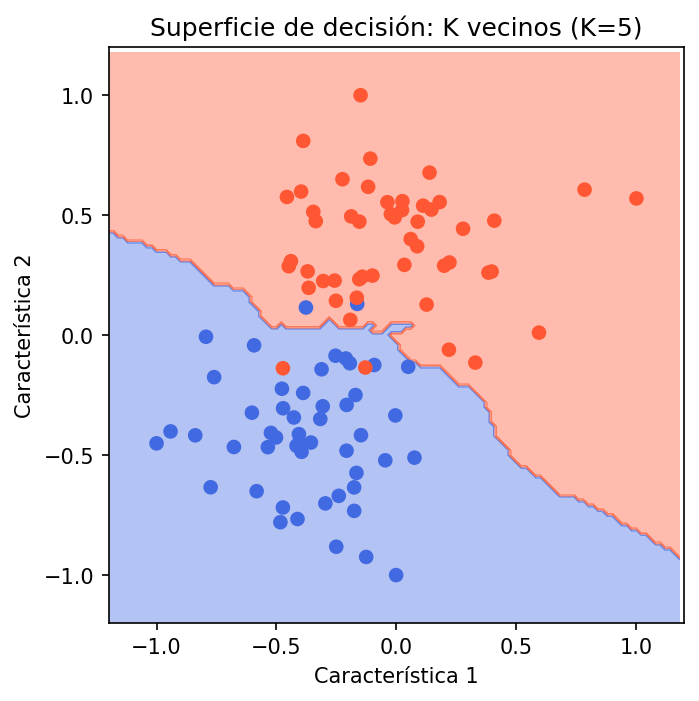
# Superficie de decisión de cada modelomodelos = [ ("SVM (MVS)", SVC(kernel='linear', C=1, random_state=1)), ("Regresión logística", LogisticRegression(random_state=1)), ("K vecinos (K=5)", KNeighborsClassifier(n_neighbors=5)),]archivos = ['02_svm', '03_logistica', '04_kvecinos']
for (nombre, modelo), archivo in zip(modelos, archivos): modelo.fit(X, y) zz = modelo.predict(grilla).reshape(xx.shape)
fig, ax = plt.subplots() ax.contourf(xx, yy, zz, cmap=cmap_clases, alpha=0.4) ax.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_clases) mismo_ejes(ax) ax.set_title(f'Superficie de decisión: {nombre}') plt.tight_layout() plt.savefig(f'{archivo}.png', dpi=150, bbox_inches='tight') plt.close()Gráficas
Conclusiones
SVM (MVS) y regresión logística obtienen la misma media de exactitud (0.95) tanto con 5 como con 10 dobleces, con desviación estándar baja (0.0447 y 0.05), lo que indica un rendimiento estable. K vecinos más cercanos (K=5) alcanza medias ligeramente menores (0.93 con 5 dobleces y 0.94 con 10 dobleces) y una desviación estándar algo mayor en 10 dobleces (0.0663), mostrando más variabilidad entre folds. En conjunto, los tres modelos clasifican bien el conjunto de datos; MVS y regresión logística se comportan de forma muy similar y algo más estable que K-NN en esta evaluación.